Hello Deep Learning: Doing some actual OCR on handwritten characters
This page is part of the Hello Deep Learning series of blog posts. You are very welcome to improve this page via GitHub!
The previous chapters have often mentioned the chasm between “deep learning models that work on my data” and “it actually works in the real world”. It is perhaps for this reason that almost all demos and YouTube tutorials you find online never do any real world testing.
Here, we are going to do it, and this will allow us to experience first hand how hard this is. We’re going to build a computer program that reads handwritten letters from a provided photo, based on the convolutional model developed earlier.
Training
All elements described in previous chapters are present in tensor-convo-par.cc. This tool can train our alphabet model, and optionally use the Adam optimizer, do dropout, weight decay, and data augmentation.
Here are its options:
Usage: tensor-convo-par [-h] [--learning-rate VAR] [--alpha VAR] [--momentum VAR]
[--batch-size VAR] [--dropout] [--adam] [--threads VAR] [--mut-on-learn]
[--mut-on-validate] state-file
Positional arguments:
state-file state file to read from [default: ""]
Optional arguments:
-h, --help shows help message and exits
-v, --version prints version information and exits
--lr, --learning-rate learning rate for SGD [default: 0.01]
--alpha alpha value for adam [default: 0.001]
--momentum [default: 0.9]
--batch-size [default: 64]
--dropout
--adam
--threads [default: 4]
--mut-on-learn augment training data
--mut-on-validate augment validation data
When this program runs, it starts with a freshly randomised state, or one read from the specified state-file. It will periodically save its state to a file called tensor-convo-par.state. So you can restart from an existing state with ease, possibly using different settings.
While the program learns, it emits statistics to a sqlite file called tensor-convo-par-vals.sqlite3 which you can use to study what is going on, as outlined in this chapter of the series.
Details on how to build and run this program can be found here.
For testing purposes, settings --adam --mut-on-learn --mut-on-validate work well. If you run it like this, you can terminate the process after 30 minutes or so, and have a decent model.
Real world input
Here is our input image, which already has a story behind it:

When I first got the OCR program working, results were very depressing. The network struggled mightily on some letters, often just not getting them right. Whatever I did, the ‘h’ would not work for example. First I blamed my own sloppy handwriting, but then I studied what the network was trained on:

Compare this to how I (& many other Europeans) write an h:
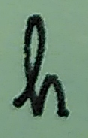
No amount of training on the MNIST set is going to teach a neural network to consistently recognize this as an h - this shape is simply not in the training set.
So that was the first lesson - really be aware of what is in your training data. If it is different from what you thought, results might very well disappoint. To make progress, I changed my handwriting in the test image to something that looks like what is actually in the MNIST data.
Practicalities
The source code of the OCR program is here, and it is around 300 lines. For image processing, I found the stb collection of single-file public domain include files very useful. To run the program, run something like ./img-ocr sample/cleaned.jpeg tensor-convo-mod.par. It will generate a file called boxed.png for you with the results in there.
So, getting started: what we have is a network that does pretty well on 28 by 28 pixel representations of letters, where the background pixel value is 0. By contrast, input images tend to have millions of pixels, in full colour even, and where black pixels have a value of 0, so the inverse of our training.
The first thing to do is to turn the image into a gray scale version, where we also adjust the white balance so black is actually black and where the gray that passes for white is actually white.
From OCR theory I learned that the first step in character segmentation is to recognize lines of text. This is done by making a graph of the total intensity per horizontal line of the image. From this graph, you then try to select intervals of high intensity that look like they might represent a line of text.
For each line, you then travel from left to right to try to box in characters.
This leads us to:

Note that this is already hard work, and not very robust. How hard this is is yet another reminder that a lot of machine learning is in fact preprocessing your data so it cooperates. Compare it to painting a house - lots of sanding and tape, and finally a fun bit of painting.
The code that does this segmentation in img-ocr.cc is none too pretty and has only been worked on so it does enough of a job that we can demo our actual neural network. (Pull requests welcome!)
Loading the network
Firing up the network is much like we did while training:
ConvoAlphabetModel m;
ConvoAlphabetModel::State s;
cout<<"Loading model state from file '"<<argv[2]<<"'\n";
loadModelState(s, argv[2]);
m.init(s, true);
auto topo = m.loss.getTopo();
Of some note is that we initialize the network with the production parameter set to true. This means that the network will not perform dropout (as described in the previous chapter). Dropout can be used during training to hide a lot of data from neural network so as to prevent overfitting.
Processing the letter
Here is the code that goes over all rectangles (stored in rects) around letters:
for(const auto& l: rects) {
cout<<"Size: cols "<< l.lstopcol-l.lstartcol<<" rows "<<l.lstoprow-l.lstartrow<<endl;
vector<uint8_t> newpic;
newpic.reserve((l.lstopcol-l.lstartcol) * (l.lstoprow-l.lstartrow));
for(int r= l.lstartrow; r < l.lstoprow; ++r) {
for(int c= l.lstartcol ; c < l.lstopcol; ++c) {
int intensity = getintens(c, r);
if(intensity < whiteballow)
newpic.push_back(255);
else if(intensity > whitebalhigh)
newpic.push_back(0);
else
newpic.push_back(255*(1- pow((intensity - whiteballow)/(whitebalhigh - whiteballow), 1) ));
}
}
This iterates over the rectangles, and the first thing it does is fix the white balance, and create a new balanced image in newpic.
Our network needs a 28x28 pixel version, which is not what we get. Usually we get a lot more pixels, but not necessarily with a square aspect ratio. To make our box square, we previously enlarged the smallest dimension so it has the same size as the largest one. From stb_image_resize.h we get functionality to do high quality resizing.
As another example of how things tend to be more difficult than you think, the MNIST training data is 28x28 pixels, BUT, the outer 2 pixels are always empty. So in fact, the network trains on 24x24 sized letters. This means that to match our image data to our network, we had best also resize letters to 24x24 pixels, and place them in the middle of a 28x28 grid:
vector<uint8_t> scaledpic(24*24);
stbir_resize_uint8(&newpic[0], l.lstopcol - l.lstartcol, l.lstoprow - l.lstartrow, 0,
&scaledpic[0], 24, 24, 0, 1);
m.img.zero();
for(unsigned int r=0; r < 24; ++r)
for(unsigned int c=0; c < 24; ++c)
m.img(2+r,2+c) = scaledpic[c+r*24]/255.0;
m.img.normalize(0.172575, 0.25);
Note that if we performed data augmentation, our network should be robust against off center letters, or pixels in the outer two rows. But let’s not make life harder than necessary for our model.
On the last line, we perform normalization as described previously so that the pixels have a similar brightness to what the network is used to. This may feel like cheating, but this kind of normalization is an objective mathematical operation. Your eyes for example do the same thing by dilating your pupils so the photoreceptor cells receive a normalized amount of photons. Those cells in turn again also change their sensitivity depending on light levels.
Next up, we can ask the network what it made of our character:
m.expected.oneHotColumn(0);
m.modelloss(0,0); // makes the calculation happen
int predicted = m.scores.maxValueIndexOfColumn(0);
cout<<"predicted: "<<(char)(predicted+'a')<<endl;
Again this is a lot like training the network, with one specific change. In this case, we honestly don’t know what letter to expect. We are asking our network to figure that out for us. However, we can’t leave the expectation value unset as this could cause out of range errors. We therefore configure expected that our expectation is 0, which corresponds to an ‘a’.
Bling
To make it pretty, the code then modifies the image to print its best guess of the letter below it:

Now, if you run the training yourself (which I encourage you to do), you’ll find that the network will always make a few mistakes. In this sample, it gets the L wrong and thinks it is a C. It does the same for the T. If you train with different settings, it will get other letters wrong.
In this animated version, recorded while a network was learning, you can see the network flip around as it is improving:
It is highly instructive to try to improve img-ocr.cc and pull requests are welcome!
But, always check what the training data say - for example, the specific form of the ’t’ that the network got wrong above is not present a lot in the training set.
{kind=link}
Also - it may be good at this point to realise we’ve written a functional OCR program, including training, in around 1800 lines of code. This is quite remarkable, and without neural networks this would never have worked.
Summarising
The initial attempt to test this network on real life data failed somewhat because the MNIST character set does not include all forms of letters (which is by design, by the way).
Secondly, we’ve learned that actually doing something with real life data requires a lot of preprocessing to actually isolate letters, fix white balance, box in characters and adjust them to what the network expects.
The end result however is quite pleasing, especially since we spent only 300 lines on ‘infrastructure’ to get the data ready for our network.
And, it should be noted that the total line count of 1500 for training and 300 for inference is impressively low.
In the next chapter you’ll find further reading & pointers where to continue your deep learning journey.