Ingegnerizzazione inversa del Codice Sorgente del Vaccino BioNTech/Pfizer
Benvenuti! In questo post daremo uno sguardo, carattere per carattere, al codice sorgente del vaccino a mRNA BioNTech/Pfizer contro il SARS-CoV-2.
Vorrei ringraziare le molte persone che hanno donato il proprio tempo a rivedere le bozze di questo articolo per migliorarne la leggibilità e la correttezza. Tutti gli errori sono miei, ma vorrei esserne informato prima possibile a bert@hubertnet.nl o @bert_hu_bert
Ora, questi termini potrebbero sembrare in contrasto - il vaccino è un liquido, che viene iniettato nel braccio. Come si può parlare di codice sorgente?
Questa è una buona domanda, e quindi cominciamo con una piccola parte del codice sorgente del vaccino BioNTech/Pfizer, anche noto come BNT162b2, anche noto come Tozinameran, anche noto come Comirnaty.

I primi 500 caratteri del mRNA BNT162b2. Fonte: World Health Organization
Nel cuore del vaccino mRNA BNT162b2 c'è questo codice digitale. E' lungo 4284 caratteri e potrebbe entrare in una trentina di tweet. Proprio all'inizio del processo di produzione, qualcuno ha caricato questo codice in una stampante a DNA (eh, già!), che ha convertito i byte sul disco in vere molecole di DNA.

Una stampante Codex DNA BioXp 3200 DNA printer
Da una simile macchina escono piccole quantità di DNA, che dopo molti passaggi chimici e biologici diventano RNA (su cui diremo fra poco) in una fiala del vaccino. Una dose di 30 microgrammi contiene appunto 30 microgrammi di RNA. In aggiunta, c'è un ingegnoso sistema di impacchettamento con lipidi (grassi), che porta il mRNA fin dentro le nostre cellule.
Il RNA è la versione volatile, la "memoria di lavoro" del DNA. Il DNA è un po' il disco a stato solido delle scienze biologiche. Il DNA è molto robusto, internamente ridondante, e molto affidabile. Ma proprio come i computer non eseguono codice direttamente da un disco a stato solido, prima che succeda una qualunque cosa, il codice viene copiato su un altro supporto, più versatile e tuttavia molto più fragile.
Per i computer si tratta della RAM; per le scienze biologiche, è il RNA. La somiglianza è stupefacente. A differenza della memoria a stato solido la RAM si degrada molto in fretta a meno che non sia amorevolmente accudita. E la ragione per la quale il vaccino a mRNA di Pfizer-BioNTech deve essere mantenuto nel più potente dei congelatori è la stessa: il RNA è un fiore delicato.
Ogni carattere del RNA pesa nell'ordine di 0.53x10-21 grammi, il che significa che in una singola dose da 30 microgrammi ci sono 6x10+16 caratteri. Espresso in byte questo viene a significare approssimativamente 25 petabyte, anche se va detto che si tratta in realtà di circa 2000 miliardi di ripetizioni dei medesimi 4284 caratteri. L'effettivo contenuto del vaccino in termini di informazione è appena sopra un kilobyte. Il virus SARS-CoV-2 stesso pesa circa 7.5 kilobyte.
Appena un pochino di background
Il DNA è un codice digitale. A differenza dei computer che usano 0 e 1, la vita usa A, C, G e U (o T), detti "nucleotidi", "nucleosidi", o "basi".
Nei computer immagazziniamo gli 0 e gli 1 come presenza od assenza di una carica, o sotto forma di corrente, come transizione magnetica, o come potenziale elettrico, o ancora come una variazione di riflettività. In breve, gli 0 e gli 1 non sono concetti astratti, bensì vivono come elettroni o come altre manifestazioni fisiche.
In natura, A, C, G e U/T sono molecole, immagazzinate come catene nel DNA (o nel RNA).
Nei computer raggruppiamo 8 bit in un byte, e il byte è la tipica unità di dati che viene elaborata.
La Natura raggruppa tre nucleotidi in un codone, e il codone è la tipica unità che prende parte all'elaborazione. Un codone contiene 6 bit di informazione (2 bit per ogni base del DNA, 3 basi = 6 bit. Questo significa che ogni codone può avere 2^6 = 64 valori diversi).
Fin qui siamo piuttosto digitali. In caso di dubbi, consultate il documento del WHO con i codici digitali che potete leggere da soli.
Un po' di letture aggiuntive sono disponibili qui; questo link ("Cos'è la vita") potrebbe aiutare a farsi una idea del resto di questa pagina. O, se preferite il video, ho due ore per voi.
Quindi, cosa FA questo codice?
L'idea dietro il vaccino è di insegnare al nostro sistema immunitario come combattere con un patogeno, senza però ammalarci veramente. Storicamente questo è stato fatto iniettando un virus indebolito o neutralizzato (attenuato), più un adiuvante che spingesse il nostro sistema immunitario all'azione. Questa era una tecnica decisamente analogica, e implicava miliardi di uova (o di insetti). Richiedeva anche un sacco di fortuna e molto di tempo. A volte, veniva usato anche un virus diverso (non collegato).
Un vaccino a mRNA ottiene lo stesso risultato ("informare il nostro sistema immunitario") ma con una precisione laser. E intendo questo in entrambi i sensi: molto preciso ma anche molto potente.
Ed ecco qui come funziona. L'iniezione contiene materiale genetico volatile, che descrive la famosa proteina "Spike" del SARS-CoV-2. Attraverso ingegnosi metodi chimici il vaccino riesce a introdurre questo materiale genetico all'interno di alcune delle nostre cellule.
Queste perciò iniziano obbedienti a produrre proteine Spike SARS-CoV-2 in quantità grandi abbastanza da fare scattare in azione il nostro sistema immunitario. Trovandosi davanti a queste proteine Spike e (importante) a segni che le cellule sono state invase, il sistema immunitario sviluppa una risposta massiccia contro diversi aspetti delle proteine Spike e contro il loro processo produttivo.
E questo è ciò che ci dà un vaccino efficiente al 95%.
Il codice sorgente!
Iniziamo proprio dall'inizio, un buon posto per cominciare. Il documento del WHO presenta questa istruttiva immagine:

Questa è una sorta di indice. Inizieremo con il "Cap", che è rappresentato con un piccolo cappello.
Proprio come non si può sbattere dei codici operativi in un file di computer e aspettarsi che funzionino, il sistema operativo biologico ha bisogno di intestazioni, linker e altre cose del tutto simili alle convenzioni di chiamata.
Il codice del vaccino inizia con questi due nucleotidi:
GA
Questo può essere paragonato molto bene a qualunque eseguibile DOS o Windows
che iniziano per MZ, o gli script Unix, che iniziano con #!. Sia nei
processi biologici che nei sistemi operativi, questi due caratteri non sono
eseguiti in alcun modo. Ma devono esserci, altrimenti nulla accade.
Il "cappello" del mRNA ha una serie di funzioni. Prima di tutto marca quel codice come di provenienza dal nucleo. Nel nostro caso naturalmente non è così, e il nostro codice viene da una vaccinazione. Ma non è necessario che lo diciamo alla cellula. Il "cappello" rende il nostro codice legittimo, e questo lo protegge dalla distruzione.
I due nucleotidi GA iniziali sono anche chimicamente un po' diversi dal resto del RNA. In questo senso, la sequenza GA contiene un po' di informazione fuori banda.
La "regione non tradotta cinque primo"
Qui serve un po' di gergo. Le molecole del RNA possono essere lette soltanto in un verso, e per confondere le cose, l'estremità dove comincia la lettura è chiamata "5'", o "cinque primo". La lettura termina all'estremità "3'" o "tre primo".
Qui abbiamo la regione non tradotta ("UTR"), cioè la parte che non finisce nella proteina
GAAΨAAACΨAGΨAΨΨCΨΨCΨGGΨCCCCACAGACΨCAGAGAGAACCCGCCACC
E qui incontriamo la prima sorpresa. I normali caratteri del RNA sono A, C, G e U. U è la molecola che nel DNA corrisponde a "T". Ma qui troviamo un Ψ: che succede?
Questo è uno dei punti estremamente ingegnosi di questo vaccino. Il nostro corpo utilizza un potente antivirus (l'originale!). Per questo motivo, le cellule sono estremamente poco amichevoli verso del RNA estraneo, e si impegnano molto per distruggerlo prima che riesca a fare qualsiasi cosa.
Questo è un po' un problema, per il nostro vaccino, che deve infiltrarsi oltrepassando il sistema immunitario. Ma dopo molti anni di esperimenti si è scoperto che se la U nell'RNA viene sostituita con una molecola diversa, il nostro sistema immunitario perde interesse. Completamente.
E così nel vaccino BioNTech/Pfizer, ogni molecola di uracile U è stata sostituita con una molecola di 1-metil-3'-pseudouridina, indicata con Ψ. E la parte ingegnosa è che anche se questa Ψ sostituita calma il nostro sistema immunitario, le parti chiave della cellula la continuano a considerare come una normale U.
Anche in sicurezza informatica conosciamo bene questo trucco: a volte è possibile inviare una versione leggermente alterata di un messaggio, che confonde i firewall e le soluzioni di sicurezza, ma che è lo stesso accettata come valida dai server che vi stanno dietro, e che in questo modo possono venire hackerati.
Oggi raccogliamo i benefici di una ricerca scientifica fondamentale svoltasi negli ultimi anni. Gli scopritori della tecnica Ψ hanno dovuto combattere, per ottenere i fondi per il loro progetto, e poi per farlo accettare. Dovremmo tutti essere loro molto grati, e credo che a tempo debito arriveranno anche i premi Nobel.
Molte persone hanno chiesto, potrebbero dei virus usare la stessa tecnica Ψ per ingannare il nostro sistema immunitario? In breve, la cosa è tremendamente improbabile. La vita non possiede il meccanismo per produrre nucleotidi di 1-metil-3'-pseudouridina. I virus usano i meccanismi della vita per riprodursi, e questo meccanismo semplicemente non è presente. I vaccini a mRNA si degradano molto in fretta, nel corpo umano, e non c'è possibilità che il RNA con Ψ sostituita si possa replicare senza perdere le Ψ. Una buona lettura è anche, "Sul serio, i vaccini a mRNA non influenzeranno il vostro DNA".
Okay, torniamo alla sequenza 5' UTR. Cosa fanno questi 51 caratteri? Come tutto in natura anche questa non ha una sola, ben definita funzione.
Quando le nostre cellule hanno bisogno di tradurre il RNA in proteine, questo viene fatto usando un meccanismo chiamato ribosoma. Il ribosoma è come una stampante 3D per proteine. Legge un filamento di RNA, e basandosi su di esso produce una sequenza di aminoacidi, che poi si ripiegheranno su loro stessi a formare una proteina.
Source: [Wikipedia utente Bensaccount](https://commons.wikimedia.org/wiki/File:Protein_translation.gif)
Questo è quello che vediamo succedere sopra. Il nastro nero in basso è l'RNA. E il nastro che appare nella zona verde è la proteina che viene fabbricata. Le cose che svolazzano in qua e in là sono gli aminoacidi, con i necessari adattatori per farli incastrare nel RNA.
Il ribosoma ha bisogno di essere fisicamente a contatto con il filamento di RNA per poter funzionare. Una volta che ci si è adattato sopra, può iniziare a formare proteine, basate sull'ulteriore RNA che entra. Da questo, potete immaginare che il ribosoma non è in grado di leggere la zona di RNA su cui si appoggia per prima. Questa è una delle funzioni della regione UTR: è la zona di atterraggio per il ribosoma. La UTR fornisce un "avvio".
Oltre a questo, la UTR fornisce dei metadati: quando dovrebbe iniziare la traduzione? E a che velocità? Per il vaccino, è stata presa la regione UTR più "Prima possibile" che si è trovata, presa dal gene per l'alfa globina. Questo gene è noto per produrre in modo molto robusto una quantità di proteine. Negli anni passati altri scienziati avevano già trovato il modo di ottimizzare ancora di più questa UTR (così dice il documento del WHO), perciò, questa non è esattamente la UTR dell'alfa globina. E' meglio.
Il peptide di segnalazione della glicoproteina S
Come si è detto, lo scopo del vaccino è indurre la cellula a produrre grossi quantitativi di proteina Spike del SARS-CoV-2. Fino a questo punto, abbiamo incontrato solo metadati e "convenzioni di chiamata" nel codice sorgente del vaccino. Ma ora entriamo nel territorio della vera proteina virale.
Abbiamo però un ultimo strato di metadati da esaminare. Quando il ribosoma (come mostrato dalla splendida animazione precedente) ha prodotto una proteina, quella proteina deve poi andare da qualche parte. Questo è codificato con la "sequenza di avvio estesa del peptide di segnalazione della glicoproteina S".
Per visualizzare questa cosa, immaginiamo che all'inizio della proteina ci sia una etichetta di qualche tipo, codificata come parte della proteina medesima. In questo caso specifico, il peptide di segnalazione dice che questa proteina deve uscire dalla cellula attraverso "il reticolo endoplasmatico". Perfino il gergo di Star Trek non arriva a tanto!
Il "peptide di segnalazione" non è molto lungo: però, quando guardiamo il codice troviamo delle differenze fra il RNA del virus e quello del vaccino.
(Notate che per semplificare la comparazione, ho sostituito le Ψ modificate con ordinarie U del RNA):
3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
Virus: AUG UUU GUU UUU CUU GUU UUA UUG CCA CUA GUC UCU AGU CAG UGU GUU
Vaccine: AUG UUC GUG UUC CUG GUG CUG CUG CCU CUG GUG UCC AGC CAG UGU GUG
! ! ! ! ! ! ! ! ! ! ! ! !
Che cosa sta succedendo, qui? Non ho diviso il RNA in gruppi di tre lettere per caso. Tre lettere di RNA formano un codone. E ogni codone codifica per uno specifico aminoacido. Il peptide di segnalazione nel vaccino consiste esattamente nei medesimi aminoacidi che sono codificati dal virus.
E allora come è possibile che il RNA sia diverso?
Ci sono 4^3 = 64 codoni differenti, dato che ci sono 4 caratteri nel RNA e ci sono tre di essi in ogni codone. Però, ci sono soltanto 20 aminoacidi diversi possibili. Questo vuole dire che più di un codone codifica per lo stesso aminoacido.
La vita utilizza la seguente tabella quasi universale per trasformare i codoni del RNA in aminoacidi:
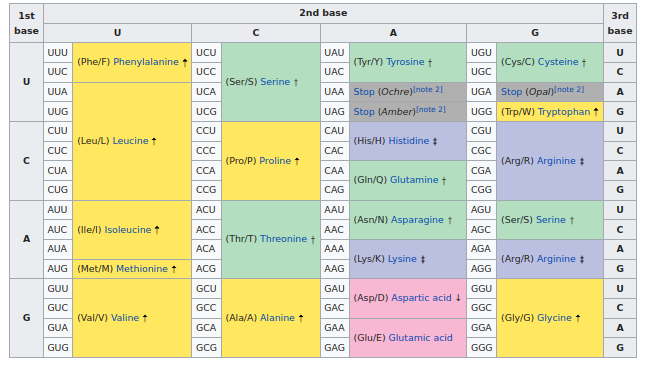
The RNA codon table (Wikipedia)
Usando questa tabella vediamo che le modifiche al vaccino (es. UUU –> UUC) sono tutte di tipo sinonimico. Il codice del RNA vaccinale è diverso, ma codifica gli stessi aminoacidi e perciò produce le medesime proteine.
Se osserviamo con attenzione, notiamo che la maggioranza dei cambiamenti avviene in terza posizione nel codone, sopra annotata con un "3". E se guardiamo la tabella universale dei codoni, vediamo che in effetti spesso questa terza posizione è irrilevante ai fini di che aminoacido viene prodotto.
Quindi, i cambiamenti sono sinonimici… ma allora perché sono lì? Guardando attentamente vediamo che tutti i cambiamenti, tranne uno, aumentano il numero di C e G.
Perché uno vorrebbe fare questo? Come si diceva prima, il nostro sistema immunitario vede di pessimo occhio un RNA "esogeno", codice RNA che arriva dal di fuori della cellula. Per sfuggire al controllo, le U nell'RNA sono già state sostituite da Ψ.
Tuttavia, risulta che un RNA con maggiori percentuali di G e C viene anche convertito con maggior efficienza in proteine.
E questo è stato ottenuto nel RNA del vaccino sostituendo altri caratteri con G e C tutte le volte che ciò è stato possibile.
Sono intrigato dall'unica modifica che non ha portato ad una ulteriore C o G, la modifica da CCA a CCU. Se qualcuno ne conosce la ragione, per favore, informatemene! Notate che so che alcuni codoni sono più comuni di altri nel genoma umano, ma ho anche letto che questo non influenza granché la velocità di traduzione.
La proteina Spike vera e propria
Anche i successivi 3777 caratteri del RNA del vaccino sono ottimizzati per aggiungere più C e G possibile. Per motivi di spazio non elencherò qui tutto il codice, e mi concentrerò su un pezzetto particolarmente speciale. Questo è il pezzetto che fa funzionare tutto, la parte che ci aiuterà a tornare a una vita normale:
* *
L D K V E A E V Q I D R L I T G
Virus: CUU GAC AAA GUU GAG GCU GAA GUG CAA AUU GAU AGG UUG AUC ACA GGC
Vaccine: CUG GAC CCU CCU GAG GCC GAG GUG CAG AUC GAC AGA CUG AUC ACA GGC
L D P P E A E V Q I D R L I T G
! !!! !! ! ! ! ! ! ! !
Qui vediamo i soliti cambiamenti di sinonimizzazione del RNA. Per esempio il primo codone CUU è stato cambiato in CUG. Questo aggiunge una G, che sappiamo aumentare la velocità di produzione delle proteine. Sia CUU che CUG codificano per l'aminoacido 'L', o Leucina, di conseguenza nella proteina nulla cambia.
Quando esaminiamo la proteina Spike nel vaccino e nel virus, tutti i cambiamenti sono dei sinonimi come questo… tranne due. E questi due li troviamo qui.
Il terzo e quarto codone, sopra, rappresentano modifiche nel codice. Gli aminoacidi K e V sono entrambi sostituiti da 'P', ossia Prolina. Per la 'K', ciò richiede tre cambiamenti, indicati con !!!, e per la 'V' ne ha richiesti due ('!!').
E scopriamo che sono questi due cambiamenti a rendere il vaccino davvero efficace.
Cosa è successo? Se guardiamo una vera particella di SARS-CoV-2 vediamo la proteina Spike sotto forma di una serie di punte (spike, appunto):
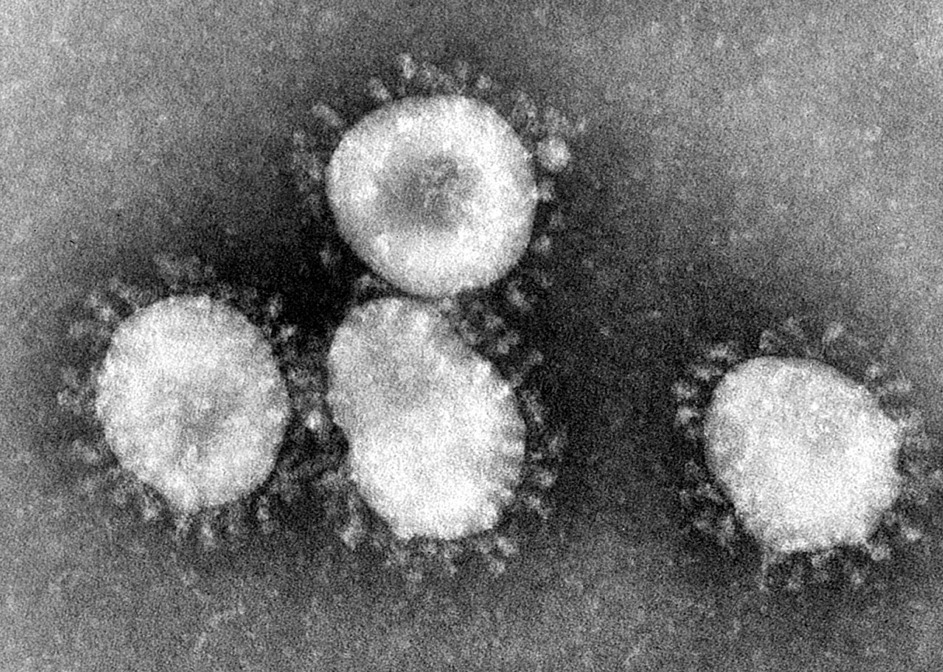
SARS virus particles (Wikipedia)
Le punte sono montate sul "corpo" virale (la "proteina nucleocapside"). Ma il fatto è che il nostro vaccino produce solo la proteina, e non la monta proprio su nessun corpo.
E se si lasciasse tale e quale, la proteina Spike libera collasserebbe su se stessa, fino a formare una struttura diversa. Se iniettassimo il vaccino con una sequenza intatta, ciò farebbe sì che il nostro corpo sviluppasse immunità, sì… ma alla proteina collassata.
E il virus SARS-CoV-2 si presenta con la proteina dritta. Il vaccino non funzionerebbe un granché, in quel caso.
E allora cosa si fa? Nel 2017, è stato descritto come la sostituzione con un doppio ponte di Prolina nel punto giusto avrebbe reso le proteine S del SARS-CoV-1 e della MERS rigide come nella loro configurazione "pre-fusione", anche senza essere collegate al vero virus. Questo perché la Prolina è un aminoacido dalla struttura molto rigida. Funge da stecca, e stabilizza la proteina nello stato che dobbiamo far riconoscere al sistema immunitario.
Le persone che hanno scoperto questo dovrebbero andare in giro dandosi il cinque a palla. Dovrebbero emanare quantità insopportabili di compiacimento. E ne avrebbero il diritto.
Aggiornamento. Sono stato contattato dal Laboratorio McLellan, uno dei gruppi dietro alla scoperta della prolina. Mi dicono che il battere il cinque è molto ridotto, a causa della pandemia in corso, ma sono contenti di avere contribuito ai vaccini. E sottolineano anche l'importanza di molti altri gruppi, lavoratori e volontari.
La fine della proteina: prossimi passi
Se andiamo avanti nel codice, troviamo alcune modifiche alla fine della proteina Spike:
V L K G V K L H Y T s
Virus: GUG CUC AAA GGA GUC AAA UUA CAU UAC ACA UAA
Vaccine: GUG CUG AAG GGC GUG AAA CUG CAC UAC ACA UGA UGA
V L K G V K L H Y T s s
! ! ! ! ! ! ! !
alla fine di una proteina troveremo un codone di "Stop", qui marcato con una s minuscola. Questo è un modo educato per dire che la proteina dovrebbe finire qui. Il virus originale usa il codone UAA per lo stop, il vaccino UGA, e ne mette due, forse per buona misura.
La "Regione Non Tradotta Tre Primo"
Proprio come il ribosoma aveva bisogno di uno spazio di inizio all'estremità 5', dove noi abbiamo potuto osservare la "Regione Non Tradotta Cinque Primo", alla fine della proteina possiamo trovare un costrutto simile denominato la 3' UTR.
Potrebbero essere scritte molte parole sulla 3' UTR, ma qui cito cosa dice Wikipedia: "La 3' UTR gioca un ruolo cruciale nell'espressione dei geni, influenzando la localizzazione, la stabilità, l'esportazione e l'efficienza di traduzione del mRNA ..nonostante la nostra attuale comprensione delle 3' UTR, rimangono ancora relativamente misteriose".
Quello che sappiamo, è che alcune 3' UTR sono molto efficaci nel promuovere l'espressione di una proteina. Secondo il documento del WHO, la 3' UTR per il vaccino BioNTech/Pfizer è stata prelevata da "the amino-terminal enhancer of split (AES) mRNA and the mitochondrial encoded 12S ribosomal RNA" per conferire stabilità al RNA ed elevata espressione proteica totale. Al che io dico, "Ben fatto!".
La fine AAAAAAAAAAAAAAAAAAAAAA di tutto
La fine del filamento di mRNA è poliadenilata. Questo è un modo fico per dire che termina con un sacco di AAAAAAAAAAAAAAAAAAAAAA. Anche l'mRNA ne ha avuto abbastanza del 2020.
Il mRNA può essere riutilizzato varie volte, ma ogni volta che succede perde alcune A che ha alla fine. Quando le A sono finite, il mRNA non è più funzionale e viene scartato. Per questo, la coda "pluri-A" è una protezione contro la degradazione.
Sono stati fatti degli studi per capire quale sia il numero ottimale di A per i vaccini a mRNA. Ho letto nella letteratura aperta che questo massimo è intorno ai 120.
Il vaccino BNT162b2 finisce con:
****** ****
UAGCAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAGCAUAU GACUAAAAAA AAAAAAAAAA
AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAA
Ossia 30 A, poi un "collegamento a 10 nucleotidi" GCAUAUGACU, seguito da altre 70 A.
Sospetto che quello che vediamo qui sia il risultato di altre ottimizzazioni proprietarie per aumentare ancora di più l'espressione della proteina.
Concludendo
Con questo, conosciamo l'esatto contenuto del mRNA del vaccino BNT162b2, e per la maggior parte possiamo capire perché sono presenti le varie sequenze:
- il cappello per assicurarsi che l'RNA sembri mRNA ordinario
- una nota, efficace ed ottimizzata regione non tradotta 5'
- un peptide di segnalazione ottimizzato per mandare la proteina Spike nel posto giusto (copiata 100% dal virus originale)
- una versione ottimizzata della proteina Spike originale, con due sostituzioni Prolina per assicurarsi che la proteina si avvolga nella forma giusta
- una nota, efficace ed ottimizzata regione non tradotta 3'
- una coda poliadenilata leggermente misteriosa con un "collegamento" non spiegato
L'ottimizzazione dei codoni aggiunge molte G e C al mRNA. Inoltre, usare 1-methyl-3’-pseudouridylyl, un aminoacido artificiale, al posto della U aiuta ad evitare il nostro sistema immunitario, così che l' mRNA possa rimanere in giro abbastanza a lungo da potere davvero aiutare ad addestrare il sistema immunitario.