A 2024 Plea for Lean Software (with running code)
This post is dedicated to the memory of Niklaus Wirth, a computing pioneer who passed away January 1st. In 1995 he wrote an influential article called “A Plea for Lean Software”, and in what follows, I try to make the same case nearly 30 years later, updated for today’s computing horrors.
The really short version: the way we build/ship software these days is mostly ridiculous, leading to 350MB packages that draw graphs, and simple products importing 1600 dependencies of unknown provenance. Software security is dire, which is a function both of the quality of the code and the sheer amount of it. Many of us know the current situation is untenable. Many programmers (and their management) sadly haven’t ever experienced anything else. And for the rest of us, we rarely get the time to do a better job.
In this post I briefly go over the terrible state of software security, and then spend some time on why it is so bad. I also mention some regulatory/legislative things going on that we might use to make software quality a priority again. Finally, I talk about an actual useful piece of software I wrote as a reality check of the idea that one can still make minimal and simple yet modern software.
I hope that this post provides some mental and moral support for suffering programmers and technologists who want to improve things. It is not just you, we are not merely suffering from nostalgia: software really is very weird today.

The state of software
Without going all ‘old man (48) yells at cloud’, let me restate some obvious things. The state of software is DIRE. If we only look at the past year, if you ran industry standard software like Ivanti, MoveIT, Outlook, Confluence, Barracuda Email Security Gateway, Citrix NetScaler ADC and NetScaler Gateway, chances are you got hacked. Even companies with near infinite resources (like Apple and Google) made trivial “worst practice” security mistakes which put their customers in danger. Yet we continue to rely on all these products.
Software is now (rightfully) considered so dangerous that we tell everyone not to run it themselves. Instead, you are supposed to leave that to an “as a service” provider, or perhaps to “the cloud”. Compare this to a hypothetical situation where cars are so likely to catch fire that the advice is not to drive a car yourself, but to leave that to professionals who are always accompanied by professional firefighters.
The assumption is then that “the cloud” is somehow able to turn insecure software into a secure service. Yet even the past year, we’ve learned that Microsoft’s email platform was thoroughly hacked, down to classified government email (update: it happened again!). There are also well-founded worries about the security of the Azure cloud. Meanwhile, industry darling Okta, which provides LOG IN SOLUTIONS got comprehensively owned. This was their second breach within a year. Also, there was a suspicious spate of Okta users getting hacked subsequently.
Clearly we need better software.
The EU has launched three pieces of legislation to this extent (NIS2 for important services, the Cyber Resilience Act for almost all commercial software and things with plugs, a revamped Product Liability Directive that extends to software). Legislation is always hard, and it remains to be seen if they got it right. But that software security is terrible enough these days to warrant legislation seems obvious.
Why software is so bad
I briefly want to touch on incentives. The situation today is clearly working well for commercial operators. Making more secure software takes time and is a lot of work, and the current security incidents all don’t appear to be impacting the bottom line or stock prices. You can speed up time to market by cutting corners. So from an economic standpoint, what we see is what you would expect. Legislation could be very important in changing this equation.
The security of software depends on two factors - the density of security issues in the source code, and the sheer amount of exposed code. As the US defense community loved to point out in the 1980s, quantity has a quality all of its own. The reverse applies to software - the more you have of it, the more risks you run.
As a case in point, Apple iPhone users got repeatedly hacked over many years because of the huge attack surface exposed by iMessage. It is possible to send an unsolicited iMessage to an Apple user, and the phone will then immediately process that message so it can preview it. The problem is that Apple in its wisdom decided that such unsolicited messages needed to support a vast array of image formats, accidentally including PDFs, including PDFs with weird embedded compressed fonts using an ancient format that effectively included a programming language.
In this way, attackers were able to benefit from security bugs in probably millions of lines of code. You don’t need a high bug density to find an exploitable hole in millions of lines of code. And nation state suppliers have found lots.
The weird thing is that Apple could have easily prevented this situation by restricting previews to a far smaller range of image formats. It is their platform, they don’t need to interoperate with anything. They could have made sending devices convert previews to a single known good image format.
But they didn’t. And to make matters worse, in 2023 they decided to add support for a new image format, which apparently was so important it had to be added outside of the security sandbox. This was again exploited.
Apple could have saved themselves an enormous amount of pain simply by exposing fewer lines of code to attackers. Incidentally, the EU Cyber Resilience Act explicitly tells vendors to minimise the attack surface.
Please do note that Apple is (by far) not the worst offender in this field. But it is a widely respected and well resourced company that usually thinks through what they do. And even they got it wrong by needlessly shipping and exposing too much code.
Could we not write better code?
It is not just the amount of code that is worrying. It is also the quality, or put another way, the density of bugs. There are many interesting things happening on this front, like the use of memory safe languages like Rust. Other languages are also upping their security game. Fuzzers are also getting ever more advanced.
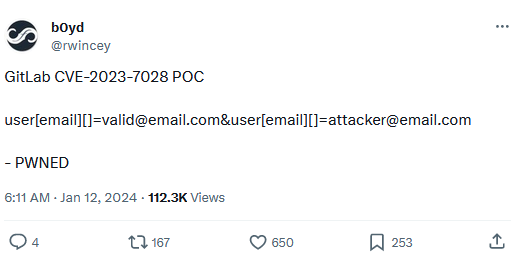
But many security problems are not so much bad code but more bad logic. A recent example is a super duper security issue in GitLab where accounts could be trivially taken over through the ‘forgot password’ functionality. Similarly, the Barracuda exploit consisted of them relying on a third party library that would actually execute code in scanned Excel sheets. The recent Ivanti exploit is similarly logic related (and extremely embarrassing).
{kind=link}
Less progress is being made on improving the logic bugs situation than on the code security front.
I’m all for writing more secure code, but as a first step, let’s look what code we are actually shipping. And do we even know?
The state of shipping software
I mean, wow, software has gotten HUGE. It is exceptionally painful to read Niklaus Wirth’s article A Plea for Lean Software from 1995, which laments that 1995 era software needed whole megabytes, and then goes on to describe the Oberon Operating System which he built which needed only 200KB, including an editor and a compiler. There are now likely projects that have more than 200KB of YAML alone.
A typical app is now built on Electron JS which incorporates both Chromium (“Chrome”) and Node.JS. From what I read, I estimate this entails at least 50 million lines of code if you include dependencies. Perhaps more. The app meanwhile likely pulls in hundreds or thousands of Node modules. Many frameworks used will also, by default, snitch on your users to advertisers and other data brokers. Incidentally, dependencies pull in further dependencies and exactly what gets included in the build can change on a daily basis, and no one really knows.
If this app controls anything in your house, it will also connect to a software stack over at Amazon, probably also powered by Node.JS, again pulling in many dependencies. And as usual, no one is even sure what it pulls in exactly as this changes from day to day.
But wait, there’s more. We used to ship software as the output of a compiler, or perhaps as a bunch of files to be interpreted. Such software then had to be installed and configured to work right. Getting your code packaged to ship like this is a lot of work. But it was good work since it forced people to think about what was in their “package”. This software package would then integrate with an operating system and with local services, based on the configuration.
Since the software ran on a fundamentally different computer than it was developed on, people really had to know what they shipped and think it through. And sometimes it didn’t work, leading to the joke where a developer tells the operations people “Well, it works on my system”, and the retort “back up your email, we’re taking your laptop in production!”.
This used to be a joke, but these days we often ship software as (Docker or other) containers, and this frequently entails effectively shipping a complete computer image. Including all the stuff that happened to be included in the build. This again vastly expands the amount of code being deployed. Note that you can do good things with Docker (see below), but there are a lot of 350+MB images on the Docker Hub.
But, all in all, we are likely looking at 50 million+ lines of code active to open a garage door, running several operating system images on multiple servers.
Now, even if all the included dependencies are golden, are we sure that their security updates are making it to your garage door opener app? I wonder how many Electron apps are still shipping with the vulnerable libwebp version in there. We don’t even know.
But even worse, it is a known fact that all these dependencies are not golden. The Node.js ecosystem has a comical history of repositories being taken over, hijacked or resurrected under the same name by someone else, someone with dire plans for your security. PyPI has suffered from similar problems. Dependencies always need scrutiny, but no one can reasonably be expected to check thousands of them frequently. But we prefer not to think about this and type ’npm install’ and observe 1600 dependencies being pulled.
Note that one should also not overshoot and needlessly reimplement everything yourself to prevent dependencies. There are very good dependencies that likely are more secure than what you could type in on your own.
Rounding off a bit, I posit that the world is 1) shipping far too much code 2) where we don’t even know what we ship and 3) we aren’t looking hard enough (or at all) at what we know we ship.
Trifecta
Writing has been called the process by which you find out you don’t know what you are talking about. Actually doing stuff meanwhile is the process by which you find out you also did not know what you were writing about.
In a very small re-enactment of Wirth’s Oberon Project, I too wrote some code to prove a point, but also to reassure myself I still know what I am talking and writing about. Can you still make useful and modern software “the old way”?
Trifecta is actual stand-alone software that you can use to paste and drag images to, for easy sharing. It has pained me for years that I had to use imgur for this purpose. Not only does imgur install lots of cookies and trackers on my browser, I also force these trackers onto the people that view the images that I share.
If you want to self-host a service like this, you also don’t want to get hacked. Most image sharing solutions I found that you could run yourself are based on huge frameworks that I don’t trust too much (given the dependency reasons outlined above). And perhaps that is my background, I used to work with a lot of classified data, and I’ve been very exposed to what the very best state sponsored hackers can do.
So, also to make a point, I decided to create a minimalistic but also useful image sharing solution that I could trust. And more important, that other people could trust as well, because you can check out the whole code within a few hours. It consists of 1600 lines of new source code, plus around 5 important dependencies (line number sizes are included in the linked article).
And this is what you then end up with:
To contrast, one other image sharing solution ships as a 311MB Docker image, although admittedly it looks better and has some more features. But not 308MB worth of them. Another comparison is this Node based picture sharing solution which clocks in at 1600 dependencies, apparently totaling 4+ million lines of JavaScript.
Trifecta is a self-contained solution with just a handful of dependencies that gives you a feature complete image sharing site:
- Full user and session management
- Drag and drop multiple images at the same time
- Posts can contain multiple images
- Each post has an optional title, each image an optional caption
- Posts can be public, or time limited public
- Passwordless accounts are possible (log in using a temporary sign-in email link)
- Lost password email flow
- One cookie, locked tight to the site
- Comes as source, binary, docker, or .deb or .rpm
- Source code small enough you could read all of it in a day
- Source code also reusable for other web frameworks
Note that this is not intended as a public site where random people can share images, as this does not tend to end well. It is however very suitable for company or personal use. You can read more about the project here, and there is also a page about the technology used to deliver such a tiny self-contained solution.
Response
This has been rather interesting. As noted earlier in this post, we have gone quite mad that we need 50+ million lines of code for a garage door opener. That we find this normal must come with some pathology.
Some years ago I did a talk at a local university on cybersecurity, titled “Have we all gone mad”. It is still worth reading today since we have gone quite mad collectively.
The most common response to Trifecta so far has been that I should use a whole bag of AWS services to deploy it. This is an exceedingly odd response to a project with the clearly stated goal of providing standalone software that does not rely on external services. I’m not sure what is going on here.
Another reaction has been that I treat Docker unfairly, and that you could definitely use containers for good. And I agree wholeheartedly. But I also look at what people are actually doing (also with other forms of containers/VMs), and that’s not so great.
I want to end this post with some observations from Niklaus Wirth’s 1995 paper.
- “To Some, complexity equals power. (…) Increasingly, people seem to misinterpret complexity as sophistication, which is baffling - the incomprehensible should cause suspicion rather than admiration.”
I’ve similarly observed that some people prefer complicated systems. As Tony Hoare noted long ago, “There are two methods in software design. One is to make the program so simple, there are obviously no errors. The other is to make it so complicated, there are no obvious errors”. If you can’t do the first variant, the second way starts looking awfully attractive perhaps.
- “Time pressure is probably the foremost reason behind the emergence of bulky software. The time pressure that designers endure discourages careful planning. It also discourages improving acceptable solutions; instead, it encourages quickly conceived software additions and corrections. Time pressure gradually corrupts an engineer’s standard of quality and perfection. It has a detrimental effect on people as well as products.”
Why spend weeks paring down your software when you can also ship a whole pre-installed operating system image that just works?
- “The plague of software explosion is not a ’law of nature’. It is avoidable, and it is the software engineer’s task to curtail it”
Now, I once studied physics, and I’m not so sure if an increase in complexity is not a law of nature. However, I do know that decreasing entropy will always cost energy. And if this is indeed on the shoulders of software people, we should perhaps demand more time for it.
Summarising
The world ships too much code, most of it by third parties, sometimes unintended, most of it uninspected. Because of this there is a huge attack surface full of mediocre code. Efforts are ongoing to improve the quality of code itself, but many exploits are due to logic bugs, and less progress has been made scanning for those. Meanwhile, great strides could be made by paring down just how much code we expose to the world. This will increase time to market for products, but legislation is around the corner that should force vendors to take security more seriously.
Trifecta is, like Wirth’s Oberon Project mentioned above, meant as a verification that you can still deliver a lot of functionality based on a limited amount of code and dependencies.
With effort and legislation, maybe the future could again bring sub-50 million line garage door openers. Let’s try to make it happen.