DNA seen through the eyes of a coder (or, If you are a hammer, everything looks like a nail)
Updates: 12th of September 2021: I’m writing a book on DNA! If you want to become a beta reader, or have suggestions, I’d love to hear from you!
8th of January 2021: This article has been revised and updated, scientifically and in terms of dead links. Revision made by Tomás Simões (@putadagravidade / tomasprsimoes@gmail.com). Feel free to contact me if I made a mistake.
25th of August 2017: This page has led to a two-hour presentation called DNA: The code of Life as presented at SHA 2017. Includes slides and video and a summarizing blogpost. If you like this page, you’ll love the presentation.
This is some rambling by a computer programmer about DNA. I’m not a molecular geneticist (Update: 20 years after starting this post, I can fake it reasonably well. This page was started somewhere in 2001, and it may need some more updating here and there. Since 2001 I’ve learned a few things and I think I need to revisit some parts of this page.)
If you spot mistakes, please contact me (@bert_hu_bert / bert@hubertnet.nl).
I’m not trying to force my view unto the DNA - each observation here is quite ‘uncramped’. To see where I got all this from, head to the Bibliography (end of the page).
The source code
Is here. This not a joke. We can wonder about the license though. Maybe we should ask the walking product of this source: Craig Venter (update: not quite true, it is mostly someone else). The source can be viewed via a wonderful set of perl scripts called ‘Ensembl’. The human genome is about 3 gigabases long, which boils down to 750 megabytes. Depressingly enough, this is only 3.6 (update: used to be 2.8, apparently Firefox decreased in size, huh.) Mozilla browsers.
DNA is not like C source but more like byte-compiled code for a virtual machine called ’the nucleus’. It is very doubtful that there is a source to this byte compilation - what you see is all you get.
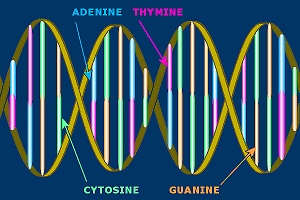
Illustration of a DNA molecule.
The language of DNA is digital, but not binary. Where binary encoding has 0 and 1 to work with (2 - hence the ‘bi’nary), DNA has 4 positions, T, C, G and A.
Whereas a digital byte is mostly 8 binary digits, a DNA ‘byte’ (called a ‘codon’) has three digits. Because each digit can have 4 values instead of 2, a DNA codon has 64 possible values, compared to a binary byte which has 256.
A typical example of a DNA codon is ‘GCC’, which encodes the amino acid Alanine. A larger number of these amino acids combined are called a ‘polypeptide’ or ‘protein’, and these are chemically active in making a living being.
See also https://www.nature.com/scitable/definition/codon-155/
Position Independent Code
Dynamically linked libraries (.so under Unix, .dll on Windows) code cannot use static addresses internally because the code may appear in different places in memory in different situations. DNA has this too, where it is called ’transposing code’:
Nearly half of the human genome is composed of transposable elements or jumping DNA. First recognized in the 1940s by Dr. Barbara McClintock in studies of peculiar inheritance patterns found in the colors of Indian corn, jumping DNA refers to the idea that some stretches of DNA are unstable and “transposable,” ie., they can move around – on and between chromosomes.
https://www.nature.com/scitable/topicpage/transposons-the-jumping-genes-518/
Conditional compilation
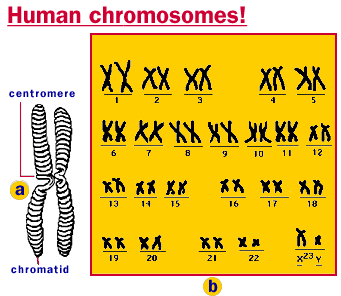
Illustration of human chromosomes.
Of the 20,000 to 30,000 genes now thought to be in the human genome (update: quite debatable), most cells express only a very small part - which makes sense, a liver cell has little need for the DNA code that makes neurons.
But as almost all cells carry around a full copy (‘distribution’) of the genome, a system is needed to #ifdef out stuff not needed. And that is just how it works. The genetic code is full of #if/#endif statements.
This is why ‘stem cells’ are so hot right now - these cells have the ability to differentiate into everything. The code hasn’t been #ifdeffed out yet, so to speak.
Stated more exactly, stem cells do not have everything turned on - they are not at once liver cells and neurons. Cells can be likened to state machines, starting out as a stem cell. Over the lifetime of the cell, during which time it may clone (‘fork()’) many times, it specializes. Each specialization can be regarded as choosing a branch in a tree.
Each cell can make (or be induced to make) decisions about its future, which each make it more specialized. These decisions are persistent over cloning using transcription factors and by modifying the way DNA is stored spatially (‘steric effects’).
A liver cell, although it carries the genes to do so, will generally not be able to function as a skin cell. There are some indications out there that it is possible to ‘breed’ cells ‘upwards’ into the hierarchy, making them pluripotent. See also this article.
Epigenetics & imprinting: runtime binary patching
Although the actual relevant changes in the DNA of an organism rarely occur within a generation, substantial tinkering goes on by activating or deactivating parts of our genome, without altering the actual code.
This can be compared to the Linux kernel, which at boot time discovers what CPU it is running on, and actually disables parts of its binary code in case (for example) it is running on a single CPU system. This goes beyond something like if(numcpus > 1), it is the actual nopping out of locking. Crucially, this nopping occurs in memory and not on the disk based image.
Similarly, as an embryo develops in the mother’s womb, its DNA is edited substantially to reduce its growth rate, and the size of the placenta. In such a way, the competing interests of the father (’large strong children’) and the mother (‘survive pregnancy’) are balanced. Such ‘imprinting’ can only happen within the mother, since the father’s genome doesn’t know anything about the size of the mother.
Recently, it is also becoming clear that the metabolic status of the parents influences the chances of long life, cancer and diabetes in their grandchildren. This also makes sense, as surviving in a food poor climate may require a different metabolic strategy than in one where food is abundantly available.
Mechanisms behind epigenetics and imprinting are ‘methylation’, which attaches methyl groups to DNA to ‘flip’ their activation status, but also histone modification, which can curl up DNA so it is not activated.
Some of these DNA edits are heritable and passed on to children, other forms may only impact one animal.
This field is still developing rapidly, and it may be that our DNA is much more dynamic than originally thought.
Dead code, bloat, comments (‘Junk DNA’)
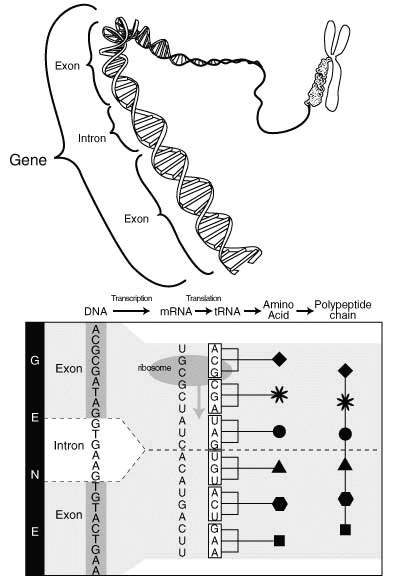
From genes to proteins.
The genome is littered with old copies of genes and experiments that went wrong somewhere in the recent past - say, the last half a million years. This code is there but inactive. These are called the ‘pseudo genes’.
Furthermore, 97% of your DNA is commented out. DNA is linear and read from start to end. The parts that should not be decoded are marked very clearly, much like C comments. The 3% that is used directly form the so called ’exons’. The comments, that come ‘in-between’ are called ‘introns’.
These comments are fascinating in their own right. Like C comments they have a start marker, like /*, and a stop marker, like */. But they have some more structure. Remember that DNA is like a tape - the comments need to be snipped out physically! The start of a comment is almost always indicated by the letters ‘GT’, which thus corresponds to /*, the end is signaled by ‘AG’, which is then like */.
However because of the snipping, some glue is needed to connect the code before the comment to the code after, which makes the comments more like html comments, which are longer: ‘<!–’ signifies the start, ‘–>’ the end.
So an actual stretch of DNA with exons and introns might look like this:
ACTUAL CODE<!-- blah blah blah blah ---- blah -->ACTUAL CODE
| | | | | |
exon 1 donor intron 1 branch acceptor exon 2
(start of comment) (end of comment)
The start of the comment is clear, which is then followed by a lot of non-coding DNA. Somewhere very near the end of the comment there is a ‘branch site’, which indicates that the comment will end soon. Then some more comment follows, and then the actual terminator.
The actual cutting of the comments happens after the DNA has been transcribed into RNA and is performed by looping the comment and bringing the pieces of actual code close together. Then the RNA is cut at the ‘branch site’ near the end of the comment, after which the ‘donor’ (comment start) and ‘acceptor’ (comment end) are connected to each other.
Now, what are these comments good for? That discussion is part of a holy war that can rival the vi/emacs one. When comparing different species, we know that some introns show fewer code changes than the neighboring exons. This suggests that the comments are doing something important.
There are lots of possible explanations for the massive amount of non-coding DNA - one of the most appealing (to a coder) has to do with ‘folding propensity’. DNA needs to be stored in a highly coiled form, but not all DNA codes lend themselves well to this.
This may remind you of RLL or MFM coding. On a hard disk, a bit is encoded by a polarity transition or the lack thereof. A naive encoding would encode a 0 as ’no transition’ and 1 as ‘a transition’.
Encoding 000000 is easy - just keep the magnetic phase unchanged for a few micrometers. However, when decoding, uncertainty creeps in - how many micrometers did we read? Does this correspond to 6 zeroes or 5? To prevent this problem, data is treated such that these long stretches of no transitions do not occur.
If we see ’no transition,no transition,transition,transition’ on disk, we can be sure that this corresponds to ‘0011’ - it is exceedingly unlikely that our reading process is so imprecise that this might correspond to ‘00011’ or ‘00111’. So we need to insert spacers so as to prevent too little transitions. This is called ‘Run Length Limiting’ on magnetic media.
The thing to note is that sometimes, transitions need to be inserted to make sure that the data can be stored reliably. Introns may do much the same thing by making sure that the resulting code can be coiled properly.
However, this area of molecular biology is a minefield! Huge diatribes rage about variants with exciting names like ‘introns early’ or ‘introns late’, and massive words like ‘folding propensity’ and ‘stem-loop potential’. I think it best to let this discussion rage on a bit.
2013 Update: ten years on, the debate still hasn’t settled! It is very clear that ‘Junk DNA’ is a misnomer, but as to its immediate function, there is no consensus. Check out Fighting about ENCODE and junk for a discussion of where we stand.
2021 Update: eighteen years on, the debate is nowhere close to being settled. It is now somewhat consensual that ‘Junk DNA’ has important and diverse functions, but new discoveries are being made on a daily basis. https://www.advancedsciencenews.com/that-junk-dna-is-full-of-information/
fork() and fork bombs (’tumors’)
Like with Unix, cells are not ‘spawned’ - they are forked. All cells started out from your ovum which has forked itself many times since. Like processes, both halves of the fork() are (mostly) identical to begin with, but they may from then on decide to do different things.
As with Unix, great problems arise when cells keep on forking. They quickly exhaust resources, sometimes leading to death. This is called a tumor. The cell is riddled with ‘ulimits’ and ‘watchdogs’ to prevent this sort of thing from happening. The number of divisions is limited by Telomere shortening, for example.
A cell cannot clone unless very stringent conditions are met - a ‘secure by default’ configuration. It is only when these safeguards fail that tumors can grow. Like with computer security, it is hard to strike a balance between security (’no cells can divide’) and usability.
Compare this to the well known Halting Problem, which is strongly associated with Alan Turing’s Machine. Perhaps it is as impossible to predict if a program will ever finish as it is to create a functional genome that cannot get cancer?
Mirroring, failover
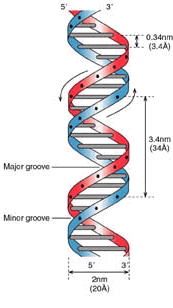
Stretch of DNA.
Each DNA Helix is redundant in itself - you can see the genome as a twisted ladder whereby each spoke contains two bases - hence the word ‘base-pair’. If one of these bases is missing, it can be derived from the one on the other side. T always binds to A, C always to G. So, we can state that the genome is mirrored within the helix. ‘RAID-1’ so to speak.
Furthermore, there are two copies of each chromosome present - one from each parent, with the notable exception of the Y chromosome, which is only present in males. The actual details are complicated - but most genes are thus present twice. In case one is broken or unsuccessfully mutated, the other independent copy is still there. This is what we would normally call ‘failover’.
Cluttered APIs, dependency hell
As proteins interact in the cell, they rely on each others’ characteristics. It has just been shown that proteins that interact with a lot of other proteins cannot evolve, or at least, only do so at a very slow rate.
They propose that this is because of great internal dependencies which inhibit the changing of the ‘contract’ of the protein. It is also noted that evolution does take place, but very slowly as both parts of the dependency need to evolve in a compatible way at the same time.
Viruses, worms
Somebody recently proposed in a discussion that it would be really cool to hack the genome and compromise it so as to insert code that would copy itself to other genomes, using the host-body as its vehicle. ‘Just like the nimda worm!’
He shortly thereafter realized that this is exactly what biological viruses have been doing for millions of years. And they are exceedingly good at it. A lot of these viruses have become a fixed part of our genome and hitch a ride with all of us. To do so, they have to hide from the virus scanner which tries to detect foreign code and prevent it from getting into the DNA.
The Central Dogma: .c -> .o -> a.out/.exe
When scientists were still discovering the basics of genetics they were faced with lots of different chemicals but the correlation was unclear. When it became clear what comes from what it was hailed as a great triumph and called ‘The Central Dogma’.
This dogma tells us that DNA is used to make RNA and that RNA is used to make proteins, which is like saying that from a .c file comes a .o object file, which can be compiled into an executable (a.out/exe). It also tells us that this is the only order in which information flows.
Now, the Central Dogma has recently been tarnished somewhat. Like any billion year old coding project, a lot of hacking has been going on, and sometimes information flows the other way. Sometimes RNA patches the DNA and at other times, the DNA is modified by proteines created earlier.
But generally, the dependencies are clear, so the Central Dogma remains important.
Binary patching aka ‘Gene therapy’
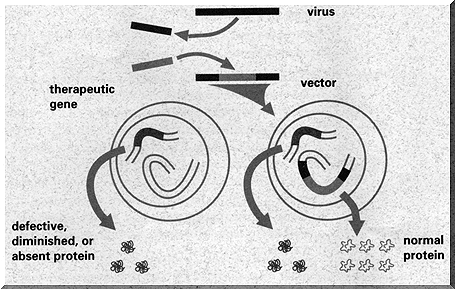
It is far harder to ‘patch the running executable’, as any programmer can attest. It is just like that with the genome. To change a running copy (‘a human’), you need to edit each and every relevant copy of the gene you want to patch.
For many years, medical science has tried to patch people with SCID, or ‘Severe Combined Immunodeficiency’, which is a very nasty disease which in effect disables the immune system - leading to very ill patients. It has been clear for quite a while now which letters in the DNA need to be fixed in order to cure these people.
Many attempts where made to patch running people, using viruses that insert new DNA into living organisms, but this proved to be very hard. The genome is guarded far too well for such a simple approach to work - cells guard their code better than Microsoft!
However, recently the right virus was found which was able to breach the protection of the genome and fix the broken characters, leading to apparently healthy people.
Bug Regression
When fixing a bug in a computer program, we often introduce new bugs in the course of doing so. The genome is rife with this thing. A lot of African Americans are immune to Malaria but instead suffer from sickle cell anemia:
In tropical regions of the world where the parasite-borne disease malaria is prevalent, people with a single copy of a particular genetic mutation have a survival advantage. (…) While inheriting one copy of the mutation confers a benefit, inheriting two copies is a tragedy. Children born with two copies of the genetic mutation have sickle cell anemia, a painful disease that affects the red blood cells.
There are quite a few examples of this happening. See also the wonderful book ‘Genome’ by Matt Ridley.
Reed-Solomon codes: ‘Forward Error Correction’
Like computer storage, DNA (and its intermediate ‘RNA’) can get corrupted. To protect against common ‘single bit errors’, the encoding from individual DNA letters to proteins is degenerate. There are 4 RNA characters, U, C, G and A - in other words, a ‘byte’ is 2 bits long. Three characters correspond to an amino acid.

6 bits could conceivably map to 64 amino acids, yet there are only 20 in use. For example, UCU, UCC, UCA and UCG all encode for ‘Serine’, whereas only UGG maps to ‘Tryptophan’. Now, it turns out that some likely ’typos’ (UCU -> UCC) in the encoding lead to an identical amino acid being expressed. For more about this fascinating phenomenon, read ‘Metamagical Themas’ by Douglas Hofstadter.
Holy Code: /* You are not expected to understand this. */
Some code is sacred. We may not remember who wrote it, or why - we just know that it works. The guy who thought it up may have left the company already. Such code is not to be tinkered with.
DNA knows the concept of the ‘molecular clock’. Some parts of the genome are actively changing and some parts are sacrosanct. A good example of the latter are the Histone genes H3 and H4.
These genes are fundamental to the actual storage of the genome and are thus of paramount importance. Any failure in this code rapidly leads to a non-functioning organism.
So it is to be expected that this code isn’t tinkered with and that turns out the case. The H3 an H4 genes have a zero effective mutation rate in humans. But it goes far beyond that. You share almost the exact same code with anything from chickens to grass or molds.
|
RATES OF NUCLEOTIDE SUBSTITUTION PER SITE PER 1000 MILLION YEARS BETWEEN
VARIOUS HUMAN AND RODENT PROTEINS-CODING GENES WITH DIVERGENCE SET AT
80 MILLION YEARS BASED ON FOSSIL EVIDENCE:
| |||||||||||||||||
Now, it does appear that there are two ways the genome can make sure that code does not mutate. The first way is described above: use amino acids that are highly degenerate and making sure that those typos that DO occur result in the same output.
Furthermore, genes can be copied earlier or later in the cell’s reproductive process, leading to more or less favorable copying conditions. Many more of such conditions apply.
It appears as if H3 and H4 were authored very carefully as they do have a lot of ‘synonymous changes’, which through the clever techniques described above do not lead to changes in the output.
Framing errors: start and stop bits
...0 0000 0001 0000 0010 0000 0011 0...
This clearly describes the 8 bit values 1, 2 and 3. The spaces I added make it clear where a byte starts and stops. Many serial devices employ stop and start bits to encode where you start reading. If we shift this sequence slightly:
...00 0000 0010 000 00100 000 00110 ...
It suddenly reads 2, 4, 6! To prevent this from happening in DNA there are elaborate signals that tell the cell where to start reading. Interestingly, there are pieces of genome that can be read from multiple starting points, and produce useful (but different) results either way. That is what I call a cool hack!
Each way a strand of DNA can be read is called an Open Reading Frame and there are generally 6, 3 each way.
Massive multiprocessing: each cell is a universe
Now, DNA is not like a computer programming language. It really isn’t. But there are some whopping analogies. We can view each cell as a CPU, running its own kernel. Each cell has a copy of the entire kernel, but choses to activate only the relevant parts. Which modules or drivers it loads, so to speak.
A cell
If a cell needs to do something (‘call a function’), it whips up the right piece of the genome and transcribes it into RNA. The RNA is then translated into a sequence of amino acids, which together make up a protein the DNA coded for. Now for the really cool bit :-)
This protein is tagged with a shipping address. This is a marker consisting of several amino acids which tell the rest of the cell where this protein needs to go. There is machinery which acts on these instructions, and delivers the protein, which is potentially on the outside of the cell.
The delivery instruction is then stripped off and several post processing steps may be performed, possibly activating the protein - which is good, because you may not want to transport an active protein through places where it should not do work.
Self hosting & bootstrapping
If we were to destroy all existing C compilers on the planet and leave only the code for one, we would be in great trouble. Yes, we have the C code to a C compiler, but we need a C compiler to compile it!
In actual fact, this was solved by not writing the first C compiler in C (duh), but in a language that was available already: B. See here for details about ‘bootstrapping’.
The same holds for the genome. To create a new ‘binary’ of a specimen, a living copy is required. The genome needs an elaborate toolchain in order to deliver a living thing. The code itself is impotent. This toolchain is commonly called ‘your parents’.
Update: Recently, it has become possible to ‘bootstrap’ life with very little actually living source material. The dictum “every cell comes from a cell” is becoming less true. See for example Mycoplasma laboratory.
It appears that RNA, which is an intermediate code between DNA and a protein, may have been the ‘B’ for DNA. Which begs the question where RNA came from. It is very interesting to note that extra-terrestrial objects often contain amino acids! See http://www.google.com/search?hl=en&q=amino+acids+meteorites
The Makefile
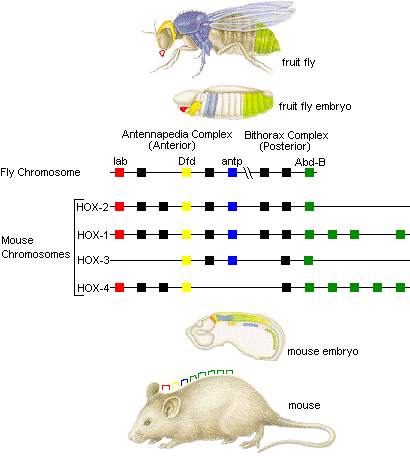
Enter the Homeobox genes. Cells must be copied and assigned a purpose. The Homeobox genes start out by laying a ’top to bottom’ dependency which reads ‘start with the head’. In order to make this happen, a chemical gradient is created by which cells can sense where they are, and decide if they need to do things useful for building a head, or for building a primordial notochord.
Only discovered in 1983, the Homeobox genes are a very exciting area of research right now. It is interesting to note that like a Makefile, ‘HOX’ genes only trigger things in other genes and don’t materially build things themselves.
The homeobox ‘syntax’ appears to be very ‘holy’ in the sense described above. What happens if you copy paste the ’legs selector’ part of a mouse HOX gene into the fruit fly Homeobox:
“In fact, when the mouse Hox-B6 gene is inserted in Drosophila, it can substitute for Antennapedia and produce legs in place of antennae”
The fruitfly and human genomes did not branch just millions of years ago but hundreds of millions of years ago. And you can copy paste parts (‘Selectors’ in the genetic language) of the Makefile and it still clicks. Please note that the ‘build a leg’ routine in a fruit fly is of course radically different from that in a mouse, but the ‘selector’ correctly triggers the right instructions.
Plugins: Plasmids
All living organisms have DNA, sometimes organized into multiple chromosomes (’libraries’), sometimes in only one, typically circular in that case. This goes for most bacteria. Next to this large main genome, such bacteria frequently also host ‘plasmids’: tiny circles of DNA with specific functions.
Such plasmids are somewhat portable between species, and through a variety of mechanisms they do indeed get transferred horizontally. By this way even non-identical bacteria can ’learn’ antibiotic resistance from each other, for example.
Compared to the programming world, a plasmid is not voluntary, and is like LD_PRELOADing a .so or the equivalent on other platforms. And in fact, plasmids are frequently injected for research purposes. They can easily be injected in all kinds of bacteria, and immediately get to work.
Plasmids copy themselves independently from the main chromosome, and are thus a permanent fixture of bacteria. To make this happen, a plasmid features the magnificently named ’Origin of Replication’ gene which gets triggered when the cell wants to divide.
Further reading
Genome by Matt Ridley
An amazing account of an effect each chromosome has on our lives. Very readable yet strict in not ‘dumbing down’ the theory. Contains an impressive set of references. Source of many of the more impressive examples found on this page. And to help Matt along in the quest he clearly sets out in his book, I would like to state quite clearly: Genes are not there to cause diseases
Human Molecular Genetics, second edition by Tom Strachan and Andrew P. Read
Neatly fills the gap between ‘primary literature’ (ie, peer reviewed academic magazines and papers) and introductory textbooks. I’m literally dragging myself through this book, constantly looking things up in order to understand everything. If you really want to know the details about introns, exons, RNA in all its variants, how genes cause and prevent diseases, this is the book.
The Selfish Gene by Richard Dawkins
Richard Dawkins is the Richard Stevens of evolution theory. Both have contributed practical work but are most famous for their crystal clear expositions of existing theory, opening up the world they describe to an audience of millions.
The Blind Watchmaker : Why the Evidence of Evolution Reveals a Universe Without Design by Richard Dawkins
Again a book by Dawkins. More about evolution than about genes but clearly explains how evolution can be responsible for the intricate design found in many living things. Again very readable and fascinating on every level.
Metamagical Themas by Douglas Hofstadter
This is an ‘idea’ book. It is filled to the brim with ideas, they simply ooze out of the pages. Many of these ideas are about information theory, genetics, life, intelligence, music, mathematics and people. Clearly not a genetic textbook but has been influential in imbuing enthusiasm for all things genetic in many people. Can often be found dirt cheap in second hand bookstores. Recommended.