Dekonstruktion des Programmcodes des BioNTech/Pfizer SARS-CoV-2 Impfstoffes
Willkommen! In diesem Artikel werden wir einen Blick auf den Programmcode des BioNTech/Pfizer SARS-CoV-2 mRNA Impfstoffes werfen, und zwar Zeichen für Zeichen.
Ich möchte Allen danken, die zur Korrektheit und Lesbarkeit dieses Artikels beigetragen haben. Für alle Fehler zeige ich mich trotzdem selbst verantwortlich, und würde von ihnen gern schnellstmöglich hören: Via bert@hubertnet.nl oder @bert_hu_bert
Hinweise zur deutschen Übersetzung bitte an f.zahn@mailbox.org oder @zahnstein
Nun, diese Worte wirken zunächst etwas verstörend - ein Impfstoff ist eine Flüssigkeit, die in meinen Arm injiziert wird. Wie kann man da von Programmcode sprechen?
Eine gute Frage, und als Einstieg sehen wir hier einen kurzen Auszug des Programmcodes des BioNTech/Pfizer Impfstoffes, auch bekannt als BNT162b2, alias Tozinameran, alias Comirnaty.

Die ersten 500 Zeichen der BNT162b2 mRNA. Quelle: World Health Organization
In ihrem Kern besteht die BNT162b2 mRNA aus einem digitalen Code. Er ist 4284 Zeichen lang, würde also in einige wenige Tweets passen. Ganz zu Beginn der Impfstoffproduktion wurde dieser Code an einen DNA-Drucker geschickt (wirklich!), welcher dann die digitale Information in tatsächliche DNA-Moleküle übersetzt hat.

Ein Codex DNA BioXp 3200 DNA-Drucker
Aus einer solchen Maschine kommt zunächst eine winzige Menge DNA, welche durch zahlreiche biologische und chemische Prozesse schlussendlich als RNA (mehr dazu später) in einem Impfstoff-Fläschchen landet. Eine solche Dosis von 30 Mikrogramm enthält tatsächlich schlicht 30 Mikrogramm RNA. Zusätzlich wird noch eine clevere Lipid-(Fett)-Verpackung zugesetzt, die die mRNA in unsere Zellen bringt.
RNA ist die flüchtige “Arbeitsspeicher”-Variante der DNA. DNA ist wie der Festplattenspeicher der Biologie - sie ist sehr widerstandsfähig, in sich redundant und ausfallsicher, und zuverlässig. Aber genau wie in Computern werden Programme nicht direkt von der Festplatte ausgeführt, sondern bevor irgend etwas passieren kann, muss der Code zunächst in einen schnelleren, vielseitigeren Speicher kopiert werden - der jedoch deutlich fragiler und anfälliger ist.
Für Computer ist dies der Arbeitsspeicher, auch bekannt als RAM, in der Biologie die RNA. Die Ähnlichkeit ist bestechend. Anders als Festplattenspeicher, verliert Arbeitsspeicher sehr schnell die enthaltene Information, wenn diese nicht regelmäßig umsorgt und aufgefrischt wird. Und der Grund, warum der Pfizer/BioNTech mRNA Impfstoff bei Tiefsttemperaturen gelagert werden muss, ist der gleiche: RNA ist ein zartes Pflänzchen.
Jedes RNA-Zeichen wiegt ungefähr 0,53·10⁻²¹ Gramm, also enthält eine einzige Dosis von 30 mg grob 6·10¹⁶ Zeichen. Ausgedrückt in Bytes sind dies rund 25 Petabyte (25000000 Gigabyte), jedoch sind dies lediglich 2000 Milliarden Wiederholungen der gleichen 4284 Zeichen. Der tatsächliche Informationsgehalt des Impfstoffes beläuft sich auf nur etwas mehr als ein Kilobyte. Der SARS-CoV-2 Virus selbst kommt auf ungefähr 7,5 Kilobyte.
Ein klitzekleines bisschen Hintergrundwissen
DNA ist ein digitaler Code. Anders als Computer, die Nullen und Einsen nutzen, setzt das Leben auf A, C, G und U/T, die sogenannten Nukleinbasen.
In Computern werden die Nullen und Einsen als An- oder Abwesenheit einer Ladung gespeichert, oder als ein elektrischer Strom, als ein magnetischer Übergang, als eine Spannung, als Modulation eines Signals, oder als ein Wechsel im Reflexionsvermögen. Kurz gesagt, 0 und 1 sind kein abstraktes Konzept, sondern existieren als Elektronen oder ähnlichem in einer physischen Verkörperung.
In der Natur sind A, C, G und U/T Moleküle, die als Ketten in der DNA (oder RNA) gespeichert werden.
In Computern fassen wir 8 Bits (0 oder 1) als ein Byte zusammen, und das Byte ist die übliche Einheit, in der Informationen verarbeitet werden.
Die Natur gruppiert 3 Nukleinbasen in ein sogenanntes Codon, und ein solches Codon ist die übliche Einheit der Informationsverarbeitung. Ein Codon enthält 6 Bits an Information (2 Bits je Zeichen mal 3 Zeichen je Codon = 6 Bits je Codon). Damit existieren 2⁶ = 64 unterschiedliche Codons.
Also alles ziemlich digital soweit. Wer das in Zweifel zieht, möge sich das offizielle WHO-Dokument ansehen, das den digitalen Code enthält.
Weiterführende Informationen gibt es hier - dieser Link (‘What is life’) hilft möglicherweise beim Verstehen des restlichen Artikels. Oder wenn man Videos bevorzugt, gibt es hier zwei Stunden davon.
Was TUT dieser Code denn nun?
Die Idee einer Impfung ist, unserem Immunsystem beizubringen einen Krankheitserreger zu bekämpfen, ohne dass wir tatsächlich krank werden. Bisher geschah dies durch die Injektion eines geschwächten oder entschärften Virus, dazu eines Hilfsstoffes, der unser Immunsystem aufschreckt und in Aktion versetzt. Dies war ein ausgesprochen analoger Prozess, unter Nutzung von Milliarden an Hühnereiern oder auch Insekten. Er erforderte auch eine Menge Glück und viel Zeit. Mitunter kam auch ein zweites, unrelatiertes Virus zum Einsatz.
Eine mRNA-Impfung erreicht das selbe Ergebnis (“erteilt unserem Immunsystem eine Lektion”), aber in einer Weise, die einem Laser ähnelt. Und dies in jeder Hinsicht - extrem präzise, und äußerst leistungsstark.
Und so funktioniert das: Die Injektion enthält flüchtiges genetisches Material, welches das berühmt-berüchtigte SARS-CoV-2 “Spike”-Protein beschreibt. Durch clevere chemische Tricks gelangt der Impfstoff in einige unserer Zellen.
Diese beginnen dann pflichtgemäß, das SARS-CoV-2 Spike-Protein in so großen Mengen zu produzieren, dass unser Immunsystem auf dieses anspringt. Die Konfrontation mit dem Spike-Protein, zusammen mit den offensichtlichen Anzeichen, dass Zellen von Viren übernommen wurden, lässt unser Immunsystem eine kraftvolle Antwort sowohl gegen das Spike-Protein als auch gegen dessen Produktionsprozess entwickeln.
Und so bekommt man einen Impfstoff, der zu 95 % wirksam ist.
Der Programmcode!
Ganz von vorn beginnt es sich bekanntlich am Besten. Die WHO-Dokumente enthalten folgende hilfreiche Abbildung:

Dies stellt quasi ein Inhaltsverzeichnis dar. Wir starten an der “cap” (Kappe), die auch als solche dargestellt ist.
Genau wie man nicht einfach Befehle in eine Datei auf einem Rechner werfen kann, um diese auszuführen, so benötigt auch das biologische Betriebssystem Kopfdateien, Systembibliotheken und Vorschriften, wie Code ausführbar gemacht werden kann.
Der Code des Impfstoffes startet mit den folgenden zwei Basen:
GA
Dies ist ganz ähnlich, wie jede ausführbare Datei auf einem DOS- oder
Windows-System mit den Zeichen MZ beginnt,
oder ein UNIX-Skript mit #!.
Sowohl das Leben selbst wie auch menschengemachte Betriebssysteme führen diese Zeichen
nicht als Befehle aus - aber sie müssen da sein, damit überhaupt etwas passiert.
Die mRNA-“cap” hat eine Vielzahl an Funktionen. So markiert sie am Code, dass dieser vom Zellkern stammt - das ist in unserem Fall zwar nicht wahr, unser Code kommt aus dem Impfstoff, aber das muss die Zelle ja nicht wissen. Die “cap” sorgt dafür, dass der Code legitim aussieht, und verhindert so, dass er zerstört wird.
Die initialen zwei GA Basen unterscheiden sich außerdem chemisch etwas vom
Rest der RNA. In diesem Sinne tragen sie weitere Informationen außerhalb der
üblichen Kodierung.
Der 5’ nicht-übersetzte Abschnitt (5’-UTR)
Zunächst ein paar Termini. RNA-Moleküle können nur in eine Richtung gelesen werden. Verwirrenderweise wird der Abschnitt, an dem das Ablesen beginnt, “5’” oder “5-Strich” genannt. Das Ablesen endet am 3’-(3-Strich)-Ende. UTR steht für UnTranslatierte Region, also “nicht-übersetzter Abschnitt”.
Organisches Leben besteht aus Proteinen (oder Dingen, die von Proteinen hergestellt werden). Und diese Proteine werden durch RNA beschrieben. Wenn RNA in Proteine umgewandelt wird, nennt man das Übersetzung (Translation).
Hier ist der 5’ nicht-übersetzte Abschnitt, welcher also nicht im Protein landet:
GAAΨAAACΨAGΨAΨΨCΨΨCΨGGΨCCCCACAGACΨCAGAGAGAACCCGCCACC
Hier erwartet uns eine erste Überraschung. Die üblichen RNA-Zeichen sind A, C, G und U, wobei U in der DNA als “T” bekannt ist. In dieser Sequenz findet sich aber ein Ψ, was ist hier los?
Dies ist eine der außergewöhnlich schlauen Lösungen im Impfstoff. Unser Körper verfügt über ein leistungsstarkes Antiviren-System (das originale “Antivirenprogramm”). Deshalb sind unsere Zellen extrem skeptisch gegenüber fremder RNA and setzen alles daran, diese zu zerstören, bevor sie irgend etwas tun kann.
Dies stellt ein ziemliches Problem für unseren Impfstoff dar - er muss sich am Immunsystem vorbei mogeln. Nach jahrelangen Experimenten wurde die Entdeckung gemacht, das man die U’s in RNA durch ein minimal modifiziertes Molekül ersetzen kann - und schon verliert das Immunsystem jegliches Interesse. Ja, wirklich.
Ergo ist im BioNTech/Pfizer Impfstoff jedes U durch 1-Methyl-3’-Pseudouridylyl ersetzt worden, welches durch Ψ symbolisiert wird. Und obwohl dieses modifizierte Ersatz-Ψ unser Immunsystem beruhigt, erkennen es alle anderen relevanten Teile der Zelle als gültiges U an.
Aus der IT-Sicherheit kennt man solche Tricks - es ist mitunter möglich, eine minimal modifizierte Version einer Nachricht zu übermitteln, die zwar Firewalls und Sicherheitslösungen verwirrt, vom Backend aber anstandslos verarbeitet wird - und welches so gehackt werden kann.
Wir ernten hier die Früchte in der Vergangenheit geleisteter wissenschaftlicher Grundlagenforschung. Die Entdecker:innen der Ψ-Ersetzungsmethode mussten dafür kämpfen, dass ihre Forschung finanziert und akzeptiert wurde. Wir sollten ihnen alle äußerst dankbar sein, und ich bin mir sicher, ein Nobelpreis ist früher oder später zu ihnen unterwegs.
Viele Leute haben nachgefragt, ob diese Ersetzungsmethode nicht auch von Viren genutzt werden könnte, um unser Immunsystem zu besiegen. In Kürze, dies ist extrem unwahrscheinlich. Lebende Organismen haben nicht die nötigen Einrichtungen, um 1-Methyl-3’-Pseudouridylyl Nukleinbasen herzustellen. Viren können nur die Maschinerie ihrer Wirtszellen nutzen, um sich fortzupflanzen, und diese verfügt schlicht nicht über diese Fähigkeit. Der mRNA-Impfstoff zerfällt sehr schnell im menschlichen Körper, und es ist ausgeschlossen, dass sich die Ψ-modifizierte RNA so reproduzieren könnte, dass ihre Replikate wieder Ψ enthielten. “No, Really, mRNA Vaccines Are Not Going To Affect Your DNA“ ist eine gute weiterführende Quelle dazu.
Okay, nun zurück zum 5’ nicht-übersetzten Abschnitt. Was tun diese 51 Zeichen? Wie die meisten Dinge in der Natur haben sie nicht nur eine einzige, klar abgegrenzte Funktion.
Wenn unsere Zellen RNA in Proteine übersetzen müssen, nutzen sie eine organische Maschine, das Ribosom. Das Ribosom ist ein 3D-Drucker für Proteine. Es nimmt Stränge an RNA auf, und basierend auf dieser Information gibt es einen Strang von Aminosäuren ab, welcher sich dann zu einem Protein faltet.
Quelle: [Wikipedia-Nutzer:in Bensaccount](https://commons.wikimedia.org/wiki/File:Protein_translation.gif)
Dies sehen wir in obigem Video. Das schwarze Band unten ist die RNA. Das Band, welches im grünen Bereich erscheint, ist das sich formende Protein. Die herumfliegenden Teile sind Aminosäuren in Kombination mit Adaptern, die an die RNA passen.
Das Ribosom muss physisch in Kontakt mit dem RNA-Strang sein, damit dies funktionieren kann. Sobald die RNA korrekt eingeführt ist, kann das Ribosom beginnen, das Protein anhand der weiteren Informationen im RNA-Strang zu formen. Man kann sich also gut vorstellen, dass das vorderste Ende des Strangs nicht abgelesen werden kann. Dies ist eine der Funktionen des nicht-übersetzten Abschnitts, es ist die Ribosom-Andockstelle.
Zusätzlich enthält der nicht-übersetzte Abschnitt übergeordnete Informationen, etwa wann und wie oft die Übersetzung in Proteine geschehen soll. Für den Impfstoff wurde die “dringlichste” bekannte Version des nicht-übersetzten Abschnitts gewählt, basierend auf dem Genom des α-Globin. Von diesem Gen ist bekannt, das es zuverlässig eine große Zahl an Proteinen herstellt. In vergangenen Jahren hatten Wissenschaftler:innen bereits herausgefunden, dass sich dieser nicht-übersetzte Abschnitt weiter optimieren lässt, was man den WHO-Dokumenten entnehmen kann. Es handelt sich also nicht genau um den nicht-übersetzten Abschnitt des α-Globin, sondern einen noch besseren.
Das S-Glykoprotein Signalpeptid
Wie bereits erwähnt ist das Ziel der Impfung, unsere Zellen Unmengen an Spike-Protein des SARS-CoV-2 Virus produzieren zu lassen. Bisher haben wir uns hauptsächlich mit übergeordneten Informationen und Ausführungsdetails des Impfungs-Programmcodes beschäftigt - nun werfen wir einen Blick auf das tatsächliche Virus-Protein.
Es gibt jedoch noch eine Schicht Metadaten, durch die wir noch durch müssen. Sobald das Ribosom ein Protein hergestellt hat (so wie in der tollen Animation oben), muss das Protein anschließend irgendwo hin. Dieser Bestimmungsort ist im “S-Glykoprotein Signalpeptid” kodiert.
Dies kann man daran erkennen, dass zu Beginn des Proteincodes eine Art Adresse angegeben ist, welche im Protein selbst enthalten ist. In unserem konkreten Fall besagt das Signalpeptid, dass dieses Protein die Zelle über das endoplasmatische Retikulum verlassen soll - ein Begriff der wohl selbst für StarTrek zu abgehoben wäre.
Das Signalpeptid ist nicht sehr lang, aber wenn wir uns den Code genau anschauen, fallen Unterschiede zwischen der Impfstoff- und der Virus-RNA ins Auge:
(Zur einfacheren Vergleichbarkeit sind hier Ψ wieder als gewöhnliche U dargestellt)
3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
Virus: AUG UUU GUU UUU CUU GUU UUA UUG CCA CUA GUC UCU AGU CAG UGU GUU
Impfstoff: AUG UUC GUG UUC CUG GUG CUG CUG CCU CUG GUG UCC AGC CAG UGU GUG
! ! ! ! ! ! ! ! ! ! ! ! !
Was ist da los? Die Gruppierung der RNA-Zeichen in Dreiergruppen ist kein Zufall, da diese je ein Codon darstellen. Und jedes Codon kodiert eine konkrete Aminosäure. Das Signalpeptid im Impfstoff besteht aus genau den gleichen Aminosäuren wie im Virus selbst.
Wie kann sich dann die RNA unterscheiden?
Wir erinnern uns: Es gibt 4³=64 unterschiedliche Codons, da es 4 unterschiedliche RNA-Zeichen gibt und 3 davon in einem Codon stecken. Andererseits gibt es jedoch nur 20 unterschiedliche Aminosäuren. In Folge dessen kodieren mehrere Codons die selbe Aminosäure.
Organisches Leben nutzt folgende, annähernd überall zutreffende Zuordnung von RNA-Codons zu Aminosäuren:
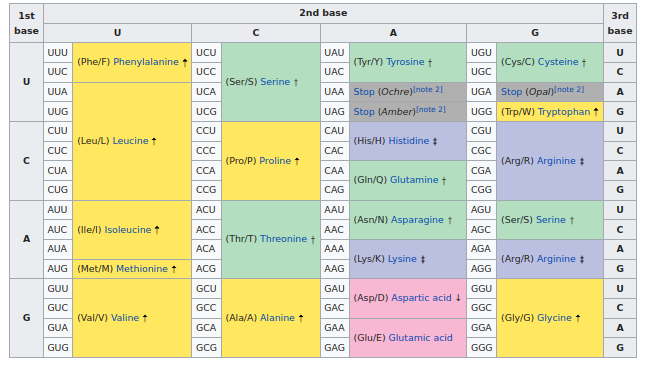
Die RNA-Codon Tabelle (Wikipedia)
In dieser Tabelle sehen wir, dass alle im Impfstoff vorgenommenen Ersetzungen (UUU -> UUC) Synonyme füreinander sind. Der RNA-Code im Impfstoff ist anders, aber es entstehen die selben Aminosäuren und das gleiche Protein.
Bei genauerem Hinschauen fällt auf, dass die meisten Ersetzungen an dritter Position im Codon vorgenommenen wurden, welche oben durch die “3” markiert wurde. Und in der Zuordnungstabelle ist ersichtlich, dass in der Tat die dritte Position häufig keine Auswirkung auf die resultierende Aminosäure hat.
Die Änderungen sind also synonym, aber warum wurden sie dann vorgenommenen? Es ist auffällig, dass alle Ersetzungen bis auf eine einzige zu mehr C’s und G’s führen.
Warum würde man das tun? Wie bereits angemerkt, ist unser Immunsystem kein Freund fremder RNA, welche nicht aus der Zelle selbst stammt. Um nicht entdeckt zu werden, wurden bereits die U’s durch Ψ’s ersetzt.
Weiterhin wurde entdeckt, dass RNA, die viele C’s und G’s enthält, effizienter in Proteine verwandelt wird.
Und zu diesem Zweck wurden in der Impfstoff-RNA möglichst viele Zeichen durch C’s und G’s ersetzt.
Ich bin fasziniert von der einen Änderung, die nicht zu einem C oder G führt, CCA -> CCU. Falls jemand weiß, was der Grund ist, bitte lass es mich wissen!
Anmerkung: Ich bin mir bewusst, dass manche Codons häufiger im menschlichen Genom vorkommen als andere, aber ich habe gelesen, dass dies keinen wesentlichen Einfluss auf die Übersetzungsgeschwindigkeit hat.
Das eigentliche Spike-Protein
Die nächsten 3777 Zeichen der Impfstoff-RNA sind in ähnlicher Weise Codon-optimiert, um viele C’s und G’s hinzuzufügen. Um Platz zu sparen, führe ich hier nicht den gesamten Code auf, aber wir werfen einen genaueren Blick auf einen besonders interessanten Teilabschnitt. Dieses Stückchen sorgt dafür, dass die Impfung wirklich ihren Job tut, und wird uns helfen, zur “Normalität” zurückzukehren.
* *
L D K V E A E V Q I D R L I T G
Virus: CUU GAC AAA GUU GAG GCU GAA GUG CAA AUU GAU AGG UUG AUC ACA GGC
Impfstoff: CUG GAC CCU CCU GAG GCC GAG GUG CAG AUC GAC AGA CUG AUC ACA GGC
L D P P E A E V Q I D R L I T G
! !!! !! ! ! ! ! ! ! !
Hier sehen wir wieder die üblichen synonymen Ersetzungen, zum Beispiel im ersten Codon von CUU zu CUG. Dieses zusätzliche G verbessert die Protein-Produktion. CUU und CUG kodieren beide die Aminosäure Leucin (‘L’), das Protein ist also unverändert.
Alle Änderungen im eigentlichen Spike-Protein-Code im Impfstoff sind solche Synonyme - bis auf zwei, und diese tauchen im obigen Abschnitt auf.
Das dritte und vierte Codon stellen eine tatsächliche Modifizierung dar. Die Aminosäuren K und V wurden durch P (Prolin) ersetzt. Im Falle des K-Codon wurden alle drei Zeichen ausgetauscht (’!!!’), beim V-Codon nur zwei (’!!’).
Diese zwei Änderungen erhöhen die Impfstoffwirksamkeit enorm.
Also was passiert hier? Wirft man einen Blick auf echte SARS-CoV-2 Viren, sieht man die Spike-Proteine als - nun ja, eine Menge Spikes.
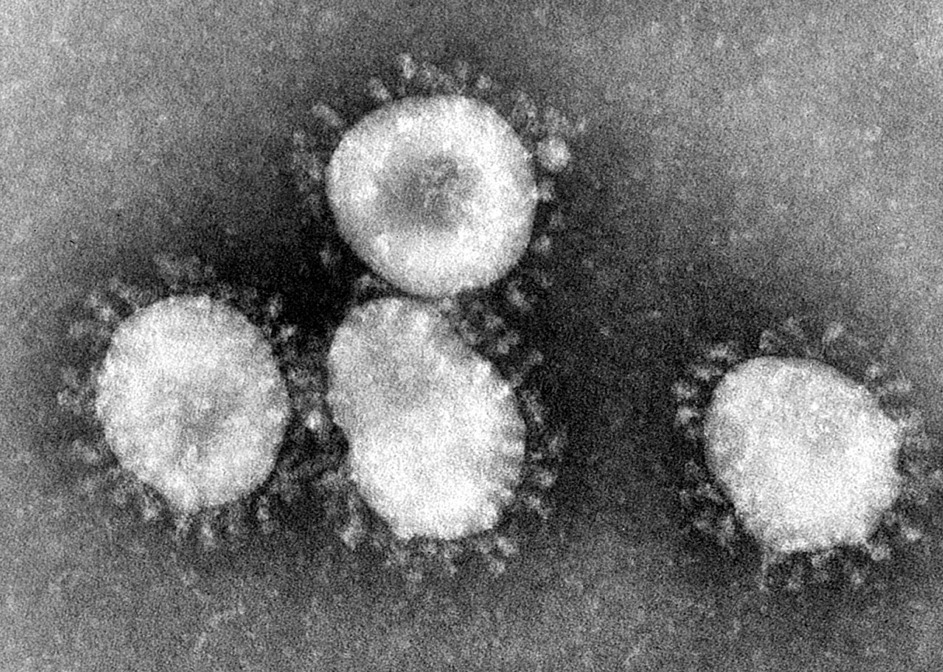
SARS Viren (Wikipedia)
Die Spikes sind auf dem Virus-Körper (dem Kapsid) befestigt. Aber: Unser Impfstoff veranlasst nur die Produktion des Spike-Proteins selbst, und diese werden an keinem Virus-Körper oder ähnlichem befestigt.
Frei stehende Spike-Proteine kollabieren jedoch in eine ganz andere Struktur. Würde man diese als Impfstoff injizieren, würde unser Körper zwar eine Immunität entwickeln… aber nur gegen das kollabierte Protein.
Das echte SARS-CoV-2 Virus wartet aber mit aufrechten Spikes auf. Die Impfung wäre nicht sehr wirksam gegen diese.
Was bleibt zu tun? 2017 veröffentlichten Forscher:innen, dass eine zweifache Prolin-Substitution an genau der richtigen Stelle dazu führt, dass das SARS-CoV-1 und MERS Spike-Protein ihre “Angriffsstellung” einnehmen, auch ohne Teil des ganzen Virus zu sein. Das klappt, da Prolin eine äußerst stabile Aminosäure ist, und so wie eine Schiene wirkt. Das Protein verbleibt in dem Zustand, in dem wir es dem Immunsystem präsentieren müssen.
Die Leute, die das entdeckt haben, sollten sich ohne Ende gegenseitig abklatschen. Unerträgliche Menge an Selbstgefälligkeit dürften sie ausstrahlen, und das völlig zu recht.
Update! Das McLellan-Labor, eine der Gruppe, die hinter der Prolin-Entdeckung steckt, hat mich kontaktiert. Sie lassen mitteilen, dass das Abklatschen pandemiebedingt ausgesetzt ist, aber sie freuen sich sehr zum Impfstoff beigetragen zu haben. Sie möchten außerdem betonen, dass zahlreiche andere Forschungsgruppen, Kolleg:innen und Freiwillige beigetragen haben.
Das Ende des Proteins und weitere Schritte
Überfliegen wir den Rest des Programmcodes, treffen wir auf weitere kleine Änderungen gegen Ende des Spike-Proteins:
V L K G V K L H Y T s
Virus: GUG CUC AAA GGA GUC AAA UUA CAU UAC ACA UAA
Impfstoff: GUG CUG AAG GGC GUG AAA CUG CAC UAC ACA UGA UGA
V L K G V K L H Y T s s
! ! ! ! ! ! ! !
Am Ende des Protein-Codes finden wir ein “Stopp”-Codon, oben durch “s” annotiert. Das ist die höfliche Art und Weise, mitzuteilen, dass hier der Protein-Code endet. Das Original-Virus nutzt das “UAA” Stopp-Codon, der Impfstoff nutzt zwei “UGA” Stopp-Codons - vielleicht nur, um auf Nummer Sicher zu gehen.
Der 3’ nicht-übersetzte Abschnitt
So wie das Ribosom eine Andockstelle in Form des 5’-Abschnitts benötigte, welcher nicht übersetzt wird, so existiert am Ende des Protein-Codes ein ähnliches Konstrukt, welches “3’ nicht-übersetzter Abschnitt” genannt wird.
Es bliebe viel zu sagen über diesen 3’-Abschnitt, aber an diese Stelle möchte ich Wikipedia zitieren: “Der 3’-Abschnitt spielt eine zentrale Rolle in der Genexpression und hat einen Einfluss auf die Lokalisierung, Stabilität, Ausstoß und Übersetzungseffizienz der mRNA… trotz unseres aktuellen Verständnis der 3’-Abschnitte, bleiben diese verhaltnismäßig rätselhaft.”
Was wir wissen, ist, dass bestimmte 3’-Abschnitte sehr erfolgreich darin sind, die Protein-Produktion zu befördern. Laut der WHO-Dokumente zum BioNTech/Pfizer Impfstoff wurde dessen 3’-Abschnitt zwischen “dem amino-terminalen Verbesserer gespaltener (AES) mRNA und mitochondrial kodierter 12S ribosomaler RNA ausgewählt, um die RNA-Stabilität und hohe Protein-Produktion sicherzustellen”. Dazu sage ich: Gut gemacht.
Das Ende des GAAAAAAAAAAAAAAnzen
Das allerhinterste Ende von mRNA ist polyadenyliert - eine ausgefallene Art auszudrücken, dass es mit zahlreichen AAAAAAAAAAAAAAAA Nukleinbasen endet. Selbst mRNA hat wohl genug von 2020.
mRNA kann immer wieder verwendet werden, verliert dabei jedoch stets einige A’s am Ende. Sobald diese aufgebraucht sind, ist die mRNA nicht mehr verwendbar und wird entsorgt. In dieser Hinsicht schützt der Poly(A)-Schwanz vor vorzeitigem Verschleiß.
In Studien wurde untersucht, was die optimale Anzahl von A’s am Ende eines mRNA Impfstoffes ist. In der frei verfügbaren Literatur dazu habe ich gelesen, dass diese Zahl von A’s um die 120 liegt.
Der BNT162b2 Impfstoff endet mit:
****** ****
UAGCAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAGCAUAU GACUAAAAAA AAAAAAAAAA
AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAA
Das sind 30 A’s, daraufhin ein Verbindungsstück aus 10 Nukleotiden (GCAUAUGACU),
gefolgt von 70 weiteren A’s.
Ich vermute, wir sehen hier das Ergebnis weiterer proprietärer Optimierungen, um die Protein-Produktion zu verbessern.
Zusammenfassung
Wir kennen nun den genauen mRNA-Inhalt des BNT162b2 Impfstoff, und zu weiten Teilen verstehen wir auch, was mit den einzelnen Abschnitten bezweckt wird:
- Die “Kappe” stellt sicher, dass die RNA aussieht wie gewöhnliche mRNA
- Ein bekanntermaßen erfolgreicher und optimierter 5’ nicht-übersetzter Abschnitt
- Ein Codon-optimiertes Signalpeptid um das Spike-Protein dort hinzuschicken, wo es gebraucht wird (eine hundertprozentige Kopie vom originalen Virus)
- Eine Codon-optimierte Variante des originalen Spikes, mit zweifacher Prolin-Substitution um das Protein in der richtigen Form zu halten
- Ein bekanntermaßen erfolgreicher und optimierter 3’ nicht-übersetzter Abschnitt
- Ein etwas rätselhafter Poly(A)-Schwanz mit einem nicht weiter erklärten Verbindungsstück
Die Codon-Optimierung erhöht den Anteil von G und C Nukleinbasen in der mRNA. Außerdem hilft die Ersetzung von U durch Ψ (1-Methyl-3’-Pseudouridylyl) dabei, vom Immunsystem unentdeckt zu bleiben, sodass die mRNA lange genug erhalten bleibt, um unser Immunsystem tatsächlich zu trainieren.
Weitere Literatur und Videos
2017 habe ich einen zweistündigen Vortrag zur DNA gehalten, den man hier sehen kann. Wie dieser Artikel richtet er sich an IT-Menschen.
Weiterhin pflege ich seit 2001 die Seite ‘DNA for programmers’.
Dir gefällt vielleicht auch diese Einführung zu unserem großartigem Immunsystem.
Schlussendlich, diese Liste an Blog-Posts enthält Materialien rund um DNA, SARS-CoV-2 und COVID.