Practical Reed-Solomon for Programmers
Recently I was doing some work decoding the new Galileo High Accuracy Service data. In short, this new service will allow Galileo (“European GPS”) users to achieve decimeter-level accuracy, which is nice. This “HAS” data is transmitted highly redundantly by making good use of Reed-Solomon encoding.
To work with this data, I attempted to learn more about Reed-Solomon and I found almost all explanations were useless to me - oodles of advanced math, but no guidance of how to use R-S in practice. And in fact, quite a lot of the math-heavy pages turned out to get practical details wrong.
The math behind Reed-Solomon is indeed very pretty, and I can understand why many explanations start with telling users about lovely Galois fields. This page meanwhile will focus on things you really need to know.
This article will not turn you into an expert on Reed-Solomon. It will however allow you to understand and use any R-S codes you have to work with. In addition, you’ll learn what R-S can and can not do, and how it relates to other error correcting systems. Finally, with this understanding, the more math heavy explanations might become more accessible.
I’d like to thank Phil Karn, KA9Q for pointing me to various interesting documents & clearing up some misunderstandings I had. Also, this page uses the fec library he built based on R. Morelos-Zaragoza’s earlier work. It is good stuff (and also part of the Linux kernel).
Reed-Solomon in practice
In short, Reed-Solomon is a cool way to protect messages against damage or partial arrival. At your choice, you can add t parity symbols to a message.
These t parity symbols then allow you to:
- recover from t/2 corrupted symbols in unknown places
- recover from t corrupted/missing symbols in known places
- detect that the message was damaged (unless there are more than t corruptions)
A symbol can be 8 bits long and equal a byte, but this does not have to be the case.
Not only is this is pretty good error resilience, it provably does not get any better than this (at least, not on a per symbol basis).
You can pick t at will, which means you can choose the level of protection you want.
What you can’t pick at will however is the length of the resulting protected block: this is always 255 bytes (when using byte-sized symbols). More generally, the length is \( 2^s-1\), where \( s\) is the symbol size in bits.
Note that for 7 bit symbols, the block size would be 127 symbols, or 889 bits in total, equivalent to around 111 bytes.
The more parity symbols you add, the less room there is for your message in the block.

(255,223)
A very common R-S configuration is what is generally described as “(255,223)”. This means that the block size N is 255, which implies that the symbol size is 8 bits. The second number means that 223 (K) of these symbols are payload, and that 255-223 = 32 (t) bytes are parity symbols.
This configuration can recover from 16 corrupted bytes, anywhere in the 255 byte sized block. These corruptions can be in the message itself or in the parity symbols, there is no difference in impact.
As an additional property, if you can tell the decoder which symbols are corrupted, you can recover from 32 “erasures”. This can be very helpful to deal with packet loss.
If there are between 16 and 32 corruptions in unknown places, R-S will at least tell you about them. If more data is corrupted, the message might become “valid” again.
What this means is that an R-S operation can lead to the following results:
- Message arrived correctly
- Message was recovered from errors/missing data
- Message was correctly recognized as corrupted, could not be recovered
- So many bits got corrupted we accidentally accepted the message as correct/recovered
Because there is no way to distinguish outcome 4 from outcomes 1 and 2, R-S is no substitute for cryptographic integrity functions!
Parameters
It is common to talk about “(255,223)” Reed-Solomon, but that description is woefully incomplete. Be aware that if (255,223) is the specification you got, this is not enough to be interoperable. Or in other words, you need to know more.
Here is the full set of parameters needed to specify a Reed-Solomon configuration:
- Symbol size in bits (often 8)
- Number of parity symbols (t or “number of roots”)
- (Padding, more about which later)
- The extended Galois field generator polynomial coefficients
- The primitive element in the Galois field used to generate the Reed Solomon code generator polynomial
- The first consecutive root of the Reed Solomon code generator polynomial
The first three items can be derived from “(255,223)”, the rest however remains to be picked.
If you have to interoperate with an existing standard, you must glean these parameters from the specification. These might be well hidden, or they might be using different words to describe the same things.
If you want to pick a configuration for your own use you will find almost no guidance online, or worse, incorrect advice.
Here is what you need to know.
For 8-bit symbols, there are two polynomials you can use:
- \( 1 + x^2 +x^3 + x^4 + x^8 \) (famously used by the NASA Voyager missions)
- \( 1 + x + x^2 + x^7 + x^8 \)
For the “primitive element”, you can pick any number under 255, as long as it is not divisible by 3, 5 or 17. This has to do with the intricacies of the Galois Field used in 8-bit R-S. In practice, people pick 11 a lot, but you could also use 7, 8, 13, 14, 16 or 19 for example. I’ve done some benchmarking, it appears 8, 11 or 14 are all among the fastest. If you use a non-8 bit symbol size, you must use other numbers (and other polynomials, which you can find here).
For the “first consecutive root”, as far as I can tell, you can pick any number under 255. For some reason people pick 121 sometimes, and I don’t know why. Perhaps because it is what Voyager did? There appears to be no impact on performance in any case.
So in sum, there are quite some parameters you must pick, but as long as you pick one of the values suggested above you should be good.
Some examples
To get a feel for how this works I wrote a small tool based on the excellent fec library by Phil Karn, KA9Q and Robert H. Morelos-Zaragoza. You can download a precompiled Linux binary here, or get the source from GitHub.
Note that this tool silently pads your message so it has the correct length, and hides this from you in the output. Do keep in mind that R-S operates on defined block sizes - you may need to include a length field yourself!
An example using 8 bytes of parity:
$ ./rscmd --nroots 8 "This is a test message"
nroots: 8
prim: 11
fcr: 121
poly: 1 + x + x^2 + x^7 + x^8
polyval: 0x187
(N,K) = (255,247)
The 8 parity bytes for "This is a test message": 7642b8e385fcf392
The parity is emitted in base 16.
All these settings can be changed at will (check out --help). Now let’s see
if decoding works. Note that the message has been corrupted:
$ ./rscmd --nroots 8 "This is a FAKE message" 7642b8e385fcf392
Fixed 4 corruptions in positions: 10 11 12 13
Recovered: This is a test message
Here we corrupted 4 bytes, which is as much as can be corrected using 8 parity bytes. And it worked! If we corrupt one position more, Reed-Solomon is guaranteed to detect this, up to 8 corruptions in total:
$ ./rscmd --nroots 8 "xHIS is a FAKE message" 7642b8e385fcf392
Fatal error: Could not correct message
However, Reed-Solomon can correct all 8 corruptions if we tell the decoder where they are:
$ ./rscmd --nroots 8 "xHIS is a FAKE message" -e 0 -e 1 -e 2 -e 3 -e 10 -e 11 -e 12 -e 13 7642b8e385fcf392
Informing decoder about 8 erasures: 0 1 2 3 10 11 12 13
Fixed 8 corruptions in positions: 0 1 2 3 10 11 12 13
Recovered: This is a test message
Finally note that you can also corrupt the parity bytes, it still works:
# vv vvvv
$ ./rscmd --nroots 8 "This IS a test message" 7642b8e385fc0000
Fixed 4 corruptions in positions: 5 6 253 254
Recovered: This is a test message
rscmd allows you to configure all Reed-Solomon parameters, including the
generator polynomial.
Using Reed-Solomon in practice
As noted, as long as we are working with 8-bit symbols, the total codeword will always be 255 bytes long.
Depending on your needs, you might want more or less protection. Do note however that computer hardware will only rarely corrupt single bytes (once they hit your programming language, that is). It is far more common that an entire sector, disk or memory bank disappears on you.
It is however very possible that your RAM corrupts single bits of data. Also, the TCP and Ethernet checksums are weak enough that corruptions can slip through undetected.
This however is so rare that you are better off relying on cryptography to detect such data integrity problems and retransmit entirely. R-S is not worth it in this domain.
With the perhaps notable exception of ZFS which on its initial introduction found heaps of corruptions happening in servers and drives.
One reason you don’t see a lot of corrupted bytes is that many transmission and storage techniques internally already use R-S or R-S-like algorithms, without this being exposed to you.
A much more common problem for programmers is the outright disappearance of data. This happens all the time - disks fail frequently, even SSDs, perhaps more so even. In addition, networks drop packets all the time.
Erasure coding
As an example, let’s say we have an audio stream we want to harden against dropped packets. Let’s say we want to add protection against 20% packet loss.
To do so, we could take 4 original packets, add 25% parity to each of them, and smear out the 4 original packets over 5 new ones, like this:
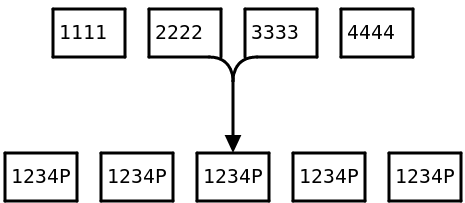
Note that we must also add a sequence number to each packet. This allows the receiver to detect exactly which packets are missing.
If nothing gets lost, the receiver waits until all 5 packets are in, and undoes the smearing out. Running the Reed-Solomon decoder will in this case only detect any (very rare) individual corrupted bytes.
But if the fourth packet got lost, things will look like this:
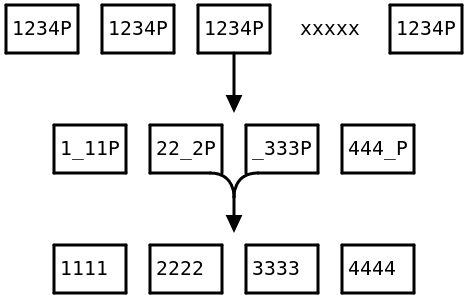
Each of the original 4 packets now has a 25% hole in it! To recover from that, the R-S decoder needs to know exactly which parts of the message got lost. And luckily we know this because we know the distribution schema and we know which packet got lost.
Thus informed, R-S is able to reconstruct the four original packets perfect, and our audio stream is not interrupted.
The above is a very simple example of how to use R-S to gain resilience against serious amounts of data loss. Do note however that it pays to put a lot of thought in such schemes. What will the packet loss look like? Might it come in bursts? And what kind of latency is acceptable? A very efficient setup might well buffer 30 seconds of data, which is useless for live interviews for example.
The scheme outlined above also works for redundant file and data storage. Many RAID6 variants use R-S more or less as described above, for example.
A few words on padding
255 bytes might simply be too large for your message. One way to deal with this is to agree on ‘padding’. As commonly implemented, if you ‘pad’ 100 bytes, this means the first 100 bytes of the 255 code block are assumed to be zero, and are not transmitted.
This turns a (255,223) code into (155,123). Using padding can save a lot of bandwidth, while not “wasting” parity. R-S continues to work just as well, even if you know none of your padding will ever get corrupted.
It is tempting to be clever about this and transmit a length field so you can do dynamically sized code word. If you do, realize you’ll also have to separately add R-S to your length field to make this safe! Otherwise a corruption in the length field might knock you out.
As an example of padding, on the GitHub page mentioned
above you can find a small tool
called
ipprotect
which uses a heavily padded 8 bits (N,K) = (6,4) code to add two additional
octets to an IP address to provide 2 symbols of R-S protection.
Some odds and ends
As noted in Theory and practice of error control codes, Reed-Solomon is indeed “perfect”, but only if your problem fits neatly on what R-S can do. The R-S block size is a hard parameter, and it might not be what you need.
Furthermore, while R-S can fix and detect damage in the maximum theoretical amount of symbols, you might not be thinking in terms of symbols, but more in terms of number of bit flips.
If x bits are flipped spaced out over your message, this will fully corrupt x symbols. Other error correcting codes might deal better with such distributed damage. R-S excels at fixing bursts of erroneous data.
Over the past few decades, a lot has been learned about error correcting codes. Modern communication protocols use things like Turbo code, Low density parity check code or the even newer-fangled Polar code. These algorithms solve the “soft decision coding” problem, which is appropriate for dealing with data sent over a noisy channel, where we deal not just with “ones and zeroes” but with probabilities of values being 1 or 0 (or many other values).
Reed-Solomon is appropriate for hard decision coding where every symbol has a clear value. Nevertheless, R-S often has a role as a concatenated (or nested) code together with a soft decision decoder.
Although very clever things are happening with LDPC and Polar codes, these appear to have no role in protecting data that does not consist of probabilities.
Summarising
- Reed-Solomon in the common 8-bit mode operates on 255 byte blocks
- You can pick how much of such a block will be parity
- If you pick t bytes, your payload is 255-t bytes
- The decoder can then correct t/2 errors in unknown locations
- It can also correct t errors in known locations (erasures)
- R-S will also reliably detect, but not fix, up to t errors
- For smaller payloads, it is possible to ‘pad’ some or even most of those 255-t payload bytes
- R-S is no substitute for cryptographic integrity checks!
- When using Reed-Solomon, be aware of exactly how it is configured, (255,223) does not tell you enough
- R-S is generally not needed to protect data on disk or during IP network transmission against individual byte errors
- R-S can however be very good at adding redundancy against dropped disks or packets
- While there is a lot of innovation for codes dealing with probabilities, LDPC, Turbo and Polar codes are not applicable for doing error correction on concrete bits and bytes
Further reading
In all my searches I mostly found confusing information or descriptions that work very well if you already understood Reed-Solomon.
Here are some documents that I found useful:
- Introduction to Reed-Solomon
- a half visual, half mathematical introduction. Very good.
- Reed-Solomon Codes - Tommaso Martini
- An introduction to Reed-Solomon codes: principles, architecture and implementation
- Reed-Solomon Encoding and Decoding. A Visual Representation - León van de Pavert
- Reed-Solomon Codes and the Exploration of the Solar System by Robert J. McEliece and Laif Swanson
- Optimizing Cauchy Reed-Solomon Codes for Fault-Tolerant Network Storage Applications
- Finite Field Arithmetic and Reed-Solomon Coding and QArt Codes (fun!) by Russ Cox
From reviews and my personal experience it is also clear that Theory and practice of error control codes (R.E. Blahut, 1983) is an extremely useful book that well deserves a reprint. As a special bonus, it contains enough math introduction that with some real work you’ll be able to truly understand the quite glorious theory behind Reed-Solomon (and many related codes). If you really want to understand the details, I highly recommend getting your hands on this book and not to try random pages on the internet.
Finally, my GitHub page for the rscmd tool outlined
above might be useful.