Een inkijkje in de broncode van het BioNTech/Pfizer SARS-CoV-2-vaccin
Vertalingen: ελληνικά / عربى / 中文 / 粵文 / bahasa Indonesia / Català / český / Deutsch / English / Español / Français / עִברִית / עִברִית2 / Hrvatski / Italiano / नेपाली / Polskie / русский / Português. / Română / Markdown for translating
Mogelijk ook interessant, en minder technisch: Hoe werken de nieuwe (mRNA) Corona Vaccins, of dit item op BNR waar ik het ook uitleg. De Belgische podcast Nerdland bespreekt deze pagina ook op heel leuke wijze (vanaf minuut 7). En afsluitend leg ik het in dit filmpje ook nog eens uit.
Welkom! In deze post neem ik alle tekens in de broncode van het BioNTech/Pfizer SARS-CoV-2 mRNA-vaccin met jullie door.
Ik wil iedereen bedanken die heeft bijgedragen aan de nauwkeurigheid en leesbaarheid van dit artikel. Eventuele fouten blijven mijn verantwoordelijkheid. Als je een fout vindt, laat dit me dan alsjeblieft weten via bert@hubertnet.nl of @bert_hu_bert. Deze vertaling is gemaakt door Marjolein Tamis, waarvoor veel dank! Vragen/opmerkingen over de vertaling graag via Twitter, @willowpje
Deze woorden klinken misschien wat vreemd, want het vaccin is een vloeistof die wordt geïnjecteerd in je arm. Waarom praten we dan over broncode?
Dat is een goede vraag. We beginnen bij een klein gedeelte van de broncode van het BioNTech/Pfizer-vaccin, dat ook BNT162b2, Tozinameran of Comirnaty wordt genoemd.

Eerste 500 tekens van het mRNA BNT162b2. Bron: World Health Organization

Een Codex DNA BioXp 3200 DNA-printer
RNA is de vluchtige variant van DNA en is vergelijkbaar met werkgeheugen. DNA is het hardeschijfgeheugen van de biologie: het is bestendig, intern redundant en heel betrouwbaar. Maar computers voeren code niet direct uit vanaf de harde schijf. Er kan pas iets met de code gebeuren nadat het is gekopieerd naar een sneller, veelzijdiger maar veel kwetsbaarder systeem.
In computers is dit RAM en in de biologie is dit RNA. Ze lijken opvallend veel op elkaar. In tegenstelling tot hardeschijfgeheugen gaat RAM-geheugen snel verloren, tenzij het regelmatig wordt ververst. Het Pfizer/BioNTech mRNA-vaccin moet dan ook om dezelfde reden in een heel koude diepvries worden bewaard: RNA is heel kwetsbaar.
Elk RNA-teken weegt ongeveer 0,53·10⁻²¹ gram. Eén vaccindosis van 30 microgram bevat dus 6·10¹⁶ tekens. Als je dit uitdrukt in bytes is dit ongeveer 25 petabytes. Ik moet er wel bij zeggen dat dit bestaat uit ongeveer 2000 miljard herhalingen van dezelfde 4284 tekens. De werkelijke informatie in het vaccin beslaat iets meer dan een kilobyte. SARS-CoV-2 zelf is ongeveer 7,5 kilobytes.
Een klein beetje achtergrondinformatie
DNA is een digitale code. Waar computers 0 en 1 gebruiken, gebruikt organisch leven A, C, G en U/T (de ’nucleotiden’, ’nucleosiden’ of ‘basen’).
In computers slaan we de 0 en 1 op als de aan- of afwezigheid van een lading, stroom, magnetische overgang, spanning, modulatie van een signaal of verandering in reflectiviteit. Kortom, de 0 en 1 zijn niet zomaar een abstract concept. Ze bestaan als elektronen of in een andere fysieke vorm.
In de natuur zijn A, C, G en U/T moleculen die als kettingen zijn opgeslagen in DNA (of RNA).
In computers groeperen we 8 bits in een byte en is de byte de gebruikelijke eenheid waarin informatie wordt verwerkt.
In de natuur worden 3 nucleotiden gegroepeerd in een codon en is het codon de verwerkingseenheid. Een codon bevat 6 bits aan informatie (2 bits per DNA-teken en 3 tekens = 6 bits. Dit betekent dat er 2⁶ = 64 verschillende codon-waarden zijn).
Tot nu toe is alles behoorlijk digitaal. Als je twijfels hebt, kun je dit zelf bekijken in het WHO-document met de digitale code.
Meer informatie vind je in mijn post What is life. Hier vind je meer achtergrondinformatie die je kan helpen om de rest van deze pagina te begrijpen. Als je liever video kijkt, vind je hier een video van twee uur.
Maar wat DOET die code eigenlijk?
Het idee van een vaccin is dat ons immuunsysteem leert hoe het een ziekteverwekker moet bestrijden, zonder dat we echt ziek worden. In het verleden werd dit gedaan door het injecteren van een verzwakt of onschadelijk gemaakt virus plus een hulpstof om ons immuunsysteem in actie te brengen. Dit was een analoge techniek waarbij miljarden eieren of insecten werden gebruikt. Er was ook veel geluk en tijd voor nodig. Soms werd ook een ander (ongerelateerd) virus gebruikt.
Met een mRNA-vaccin leert het immuunsysteem dezelfde les, maar dit vaccin werkt als een laser. Daarmee bedoel ik dat het heel precies maar ook heel krachtig is.
Het werkt zo: de injectie bevat vluchtig genetisch materiaal dat het beruchte SARS-CoV-2 ‘Spike’-eiwit beschrijft. Via een slim chemisch proces zorgt het vaccin ervoor dat dit genetische materiaal in enkele van onze cellen komt.
Deze cellen beginnen vervolgens met het produceren van SARS-CoV-2 Spike-eiwitten in zulke grote hoeveelheden dat ons immuunsysteem aan het werk gaat. Wanneer ons immuunsysteem te maken krijgt met Spike-eiwitten en duidelijke tekenen ziet dat cellen zijn overgenomen, ontwikkelt het een krachtige reactie tegen meerdere aspecten van het Spike-eiwit en het productieproces.
En zo krijgen we een vaccin dat 95% effectief is.
De broncode!
We gaan heel eenvoudig beginnen, dus dat is gewoon vooraan. In het WHO-document staat deze handige afbeelding:

Op een computer kun je niet zomaar opcodes in een bestand zetten om ze uit te voeren. Ook het biologische besturingssysteem heeft headers, ’linkers’ (koppelingen) en ‘calling conventions’ nodig.
De code van het vaccin begint met de volgende twee nucleotiden:
GA
Dit is vergelijkbaar met elk uitvoerbaar DOS- en Windows-bestand dat begint met MZ, of UNIX-scripts die beginnen met #!. Zowel op besturingssystemen als in de natuur worden deze twee tekens op geen enkele manier uitgevoerd, maar ze moeten er wel staan omdat er anders niets gebeurt.
De mRNA-‘cap’ heeft een aantal functies. Ten eerste geeft de ‘cap’ aan dat de code afkomstig is uit de celkern. In ons geval is dat natuurlijk niet zo, want onze code komt uit een vaccinatie. Maar de cel hoeft dit niet te weten. De ‘cap’ zorgt ervoor dat onze code er legitiem uitziet en dus niet vernietigd wordt.
De eerste twee nucleotiden GA zijn ook chemisch iets anders dan de rest van het RNA. In die zin bevat de GA ook een vorm van out-of-band-signalering.
Het 5’ niet-getransleerde gebied (‘five-prime untranslated region’ of 5’-UTR)
Hier gebruiken we wat jargon. RNA-moleculen kunnen maar in één richting worden gelezen. Verwarrend genoeg begint het lezen bij het gedeelte dat we 5’ or ‘vijf-accent’ noemen. Het lezen stopt bij de kant 3’ of ‘drie-accent’.
Leven bestaat uit eiwitten (of dingen die worden gemaakt door eiwitten), en deze eiwitten worden beschreven in RNA. Wanneer RNA wordt omgezet in eiwitten, noemen we dit translatie.
Dit is het 5’ niet-getransleerde gebied (‘UTR’), dat niet in het eiwit terecht komt:
GAAΨAAACΨAGΨAΨΨCΨΨCΨGGΨCCCCACAGACΨCAGAGAGAACCCGCCACC
Hier stuiten we op de eerste verrassing. De gebruikelijke RNA-tekens zijn A, C, G en U, waarbij U ook bekend staat als ‘T’ in DNA. Maar hier zien we een Ψ. Wat is hier aan de hand?
Dit is een van de bijzonder slimme oplossingen in het vaccin. Ons lichaam heeft een krachtig antivirussysteem (het originele ‘antivirusprogramma’). Daarom zijn cellen buitengewoon skeptisch over vreemd RNA en proberen ze dit heel hard te vernietigen voordat het iets kan doen.
Dit is een probleem voor ons vaccin, want het moet ons immuunsysteem kunnen omzeilen. Na jarenlang experimenteren hebben we ontdekt dat als je de U in RNA vervangt door een iets aangepast molecuul, ons immuunsysteem geen interesse meer heeft. Ja, dat is echt waar.
Daarom is in het BioNTech/Pfizer-vaccin elke U vervangen door het molecuul 1-methyl-3’-pseudouridylyl, en dit wordt aangegeven met het symbool Ψ. Het slimme is dat deze vervangende Ψ ons immuunsysteem wel sust (kalmeert), maar door relevante delen van de cel toch wordt geaccepteerd als een normale U.
Bij computerbeveiliging kennen we deze truc ook. Soms is het mogelijk om een enigszins aangepaste versie van een bericht te verzenden dat verwarrend is voor firewalls en beveiligingsoplossingen, maar toch wordt geaccepteerd door de back-endservers - die vervolgens kunnen worden gehackt.
Nu plukken we de vruchten van baanbrekend wetenschappelijk onderzoek uit het verleden. De ontdekkers van deze Ψ-techniek hebben ervoor moeten vechten om hun werk gefinancierd en geaccepteerd te krijgen. We zouden ze heel dankbaar moeten zijn, en ik weet zeker dat ze vroeg of laat een Nobel-prijs krijgen.
Veel mensen hebben gevraagd of virussen de Ψ-techniek ook kunnen gebruiken om ons immuunsysteem te verslaan. Om kort te gaan: dit is heel onwaarschijnlijk. Levende organismen hebben gewoonweg niet de middelen om 1-methyl-3’-pseudouridylyl-nucleotiden te maken. Virussen hebben de machinerie in de cellen nodig om zich voort te planten, en de cellen hebben dit vermogen niet. De mRNA-vaccins worden snel afgebroken in het menselijk lichaam en het is niet mogelijk dat het met Ψ aangepaste RNA zich vermenigvuldigt met de Ψ er nog in. “No, Really, mRNA Vaccines Are Not Going To Affect Your DNA” is ook een goed artikel over dit onderwerp.
Oké, terug naar het 5’-UTR. Wat doen deze 51 tekens? Zoals alles in de natuur heeft bijna niets één duidelijke functie.
Wanneer onze cellen RNA moeten transleren naar eiwitten, wordt dit gedaan met behulp van een machine die het ribosoom wordt genoemd. Het ribosoom is een soort 3D-printer voor eiwitten. Het neemt een RNA-streng op en geeft op basis daarvan een reeks aminozuren af, die zich vervolgens samenvouwen tot een eiwit.
Bron: [Wikipedia-gebruiker Bensaccount](https://commons.wikimedia.org/wiki/File:Protein_translation.gif)
Dit ribosoom moet fysiek op de RNA-streng zitten om aan het werk te gaan. Wanneer het ribosoom op zijn plek zit, kan het eiwitten gaan vormen op basis van het RNA dat het opneemt. Nu kun je je voorstellen dat het ribosoom de delen waar het als eerste op landt nog niet kan lezen. Dit is slechts één van de functies van het UTR: de landingsplek voor het ribosoom. Het UTR geeft een inleiding.
Daarnaast bevat het UTR ook metadata, zoals wanneer en hoe vaak het RNA getransleerd moet worden. Voor het vaccin hebben de wetenschappers het meest ‘urgente’ UTR gebruikt die ze konden vinden. Dit UTR komt uit het gen alfaglobine. Van dit gen is bekend dat het op een betrouwbare manier veel eiwitten produceert. In de afgelopen jaren hebben wetenschappers nieuwe manieren gevonden om dit UTR nog verder te optimaliseren (zie het WHO-document), dus dit is niet helemaal het alfaglobine-UTR. Het is zelfs beter.
De S-glycoproteïne signaalpeptide
Zoals vermeld is het doel van het vaccin om de cel grote hoeveelheden van het SARS-CoV-2 Spike-eiwit te laten produceren. Tot nu toe hebben we vooral gekeken naar metadata en ‘calling conventions’ in de broncode van het vaccin. Nu gaan we kijken naar de eiwitten van het virus zelf.
Eerst komt er echter nog één laag metadata. Zodra het ribosoom een eiwit heeft gemaakt (zoals in de prachtige animatie hierboven), moet dat eiwit ergens heen. Dit is gecodeerd in de ‘S-glycoproteïne signaalpeptide’.
Je kunt het zo zien: aan het begin van het eiwit staat een soort adreslabel, dat is gecodeerd als onderdeel van het eiwit zelf. In dit specifieke geval geeft de signaalpeptide aan dat dit eiwit de cel moet verlaten via het ’endoplasmatisch reticulum’. Star Trek-taal is er niets bij!
De ‘signaalpeptide’ is niet erg lang, maar als we naar de code kijken zien we verschillen tussen het virale RNA en het vaccin-RNA:
(Voor de vergelijking heb ik de aangepaste Ψ vervangen door een RNA-U)
3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
Virus: AUG UUU GUU UUU CUU GUU UUA UUG CCA CUA GUC UCU AGU CAG UGU GUU
Vaccin: AUG UUC GUG UUC CUG GUG CUG CUG CCU CUG GUG UCC AGC CAG UGU GUG
! ! ! ! ! ! ! ! ! ! ! ! !
Wat is hier aan de hand? Het is geen toeval dat het RNA wordt weergegeven in groepjes van 3 letters. Drie RNA-tekens vormen samen een codon, en elk codon codeert voor een specifiek aminozuur. De signaalpeptide in het vaccin bestaat uit precies dezelfde aminozuren als de signaalpeptide in het virus zelf.
Waarom is het RNA dan anders?
Zoals je nog weet zijn er vier verschillende RNA-tekens. Met drie tekens in een codon zijn er 4³ = 64 verschillende codons. Toch zijn er maar 20 verschillende aminozuren. Dit betekent dat meerdere codons coderen voor hetzelfde aminozuur.
Organisch leven volgt deze bijna universele tabel om RNA-codons toe te wijzen aan aminozuren:
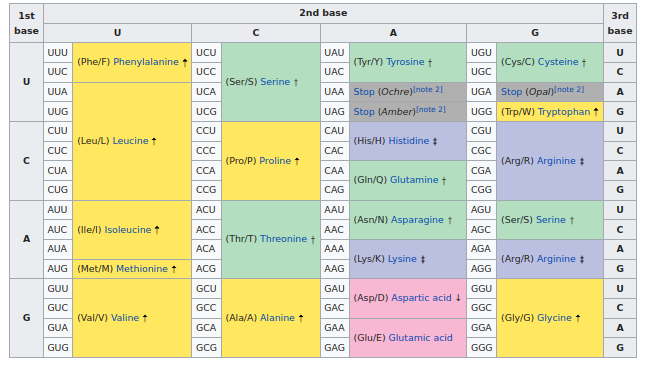
De tabel met RNA-codons (Wikipedia)
Als we goed kijken, zien we dat de meeste veranderingen zijn doorgevoerd in de derde positie van het codon, waarboven je een ‘3’ ziet. En als we de universele codontabel bekijken, zien we dat deze derde positie inderdaad vaak niet uitmaakt bij het bepalen welk aminozuur wordt geproduceerd.
De veranderingen zijn dus synoniem, maar waarom zijn ze er dan? Zoals je kunt zien, leiden alle veranderingen op één na tot meer C’s en G’s.
Maar waarom zou je dat doen? Zoals vermeld staat ons immuunsysteem zeer negatief tegenover ’exogeen’ RNA, ofwel RNA-code die van buiten de cel komt. De ‘U’ in het RNA is al vervangen door een Ψ, zodat het RNA onopgemerkt blijft.
Maar het blijkt dat RNA met een hoger aantal G’s en C’s ook efficiënter wordt omgezet in eiwitten.
En om dit doel te bereiken zijn in het vaccin-RNA zoveel mogelijk tekens vervangen door C’s en G’s.
Ik ben gefascineerd door de verandering CCA -> CCU, de enige verandering die niet heeft geleid tot een extra C of G. Als iemand weet waarom, laat dit dan alsjeblieft weten! Opmerking: ik weet dat sommige codons vaker voorkomen in het menselijk genoom dan andere, maar ik heb ook gelezen dat dit niet veel invloed heeft op de snelheid van translatie.
Het Spike-eiwit zelf
De volgende 3777 tekens van het vaccin-RNA zijn op dezelfde manier ‘codon-geoptimaliseerd’, waarbij veel C’s en G’s zijn toegevoegd. Ik zet hier niet de volledige code neer om ruimte te besparen, maar we gaan kijken naar een heel bijzonder stukje code. Dit is het stukje waardoor het werkt, het deel waardoor we straks weer terug kunnen naar het normale leven:
* *
L D K V E A E V Q I D R L I T G
Virus: CUU GAC AAA GUU GAG GCU GAA GUG CAA AUU GAU AGG UUG AUC ACA GGC
Vaccin: CUG GAC CCU CCU GAG GCC GAG GUG CAG AUC GAC AGA CUG AUC ACA GGC
L D P P E A E V Q I D R L I T G
! !!! !! ! ! ! ! ! ! !
Hier zien we de gebruikelijke synonieme RNA-veranderingen. In het eerste codon zien we bijvoorbeeld dat CUU is veranderd in CUG. Daarmee voegen we een ‘G’ toe aan het vaccin, en we weten dat dit helpt om de productie van eiwitten te verbeteren. CUU en CUG coderen allebei voor het aminozuur ‘L’ of Leucine, dus er is niets veranderd aan het eiwit.
Alle veranderingen in het Spike-eiwit van het vaccin zijn op deze manier synoniem, op twee na. Deze veranderingen zie je hierboven.
Het derde en vierde codon hierboven bevatten echte veranderingen. De aminozuren ‘K’ en ‘V’ in deze codons zijn allebei vervangen door ‘P’ of Proline. Bij ‘K’ waren hiervoor drie veranderingen nodig (’!!!’) en bij ‘V’ maar twee (’!!’).
Het blijkt dat het vaccin veel efficiënter wordt door deze twee veranderingen.
Wat gebeurt hier? In een echt SARS-CoV-2-deeltje ziet het Spike-eiwit eruit als eenaantal stekels:
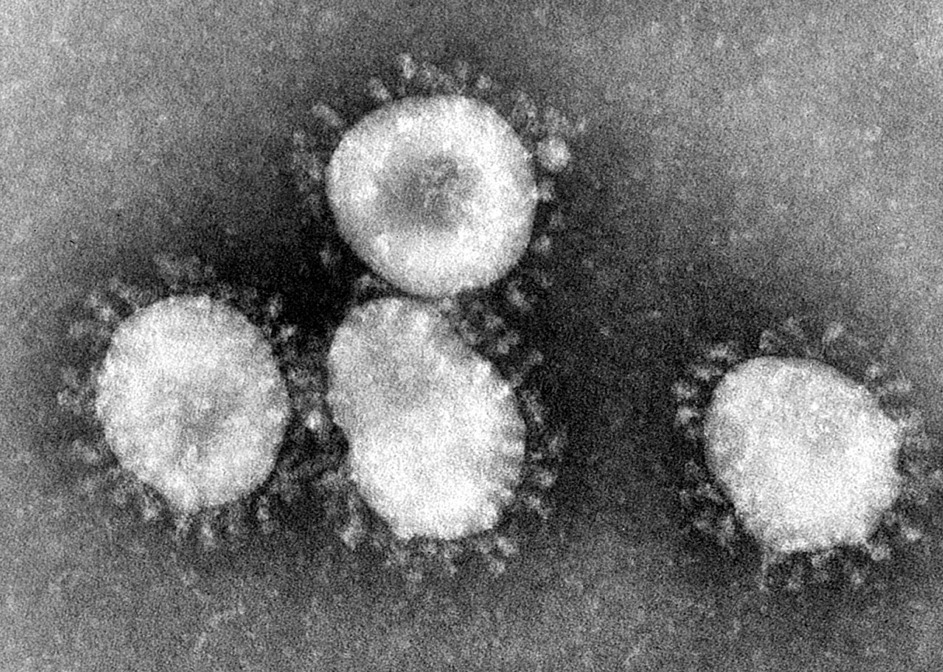
Deeltjes van het SARS-virus (Wikipedia)
Het blijkt dat onaangepaste, vrijstaande Spike-eiwitten instorten en dus een andere structuur krijgen. Als we dit gebruikten in een vaccin, zouden onze lichamen alleen immuniteit opbouwen tegen het ingestorte Spike-eiwit.
Het echte SARS-CoV-2 heeft natuurlijk een stekelig Spike-eiwit, dus het vaccin zou in dat geval niet zo goed werken.
Wat doen we hieraan? In 2017 hebben wetenschappers beschreven dat een dubbele vervanging van Proline op de juiste plek ervoor zorgt dat de SARS-CoV-1- en MERS S-eiwitten hun aanvalspositie innemen, ook zonder deel uit te maken van het hele virus. Dit werkt omdat Proline een heel stabiel aminozuur is. Het werkt als een soort spalk en stabiliseert het eiwit in de vorm die we aan het immuunsysteem moeten laten zien.
De mensen die dit hebben ontdekt zouden zichzelf eindeloos schouderklopjes moeten geven. Ze zijn vast enorm tevreden over zichzelf en dat is helemaal terecht.
Update! Het McLellan-lab, een van de groepen achter de Proline-ontdekking, heeft contact met mij gezocht. Zij vertellen me dat ze wat ingetogen zijn vanwege de aanhoudende pandemie, maar ze zijn blij dat ze hebben bijgedragen aan de vaccins. Ze benadrukken ook het belang van vele andere groepen, medewerkers en vrijwilligers.
Het einde van het eiwit en volgende stappen
Als we door de rest van de broncode bladeren, zien we enkele kleine aanpassingen aan het einde van het Spike-eiwit:
V L K G V K L H Y T s
Virus: GUG CUC AAA GGA GUC AAA UUA CAU UAC ACA UAA
Vaccin: GUG CUG AAG GGC GUG AAA CUG CAC UAC ACA UGA UGA
V L K G V K L H Y T s s
! ! ! ! ! ! ! !
Aan het einde van een eiwit vinden we een ‘stop’-codon, hier aangegeven met een kleine letter ’s’. Dit is een beleefde manier om aan te geven dat het eiwit hier moet eindigen. Het virus zelf gebruikt de stop-codon UAA en het vaccin gebruikt twee stop-codons UGA. Misschien is dit gewoon voor de zekerheid.
Het 3’ niet-getransleerde gebied
Zoals je nog weet had het ribosoom een inleiding nodig aan de 5’-kant, in de vorm van het 5’ niet-getransleerde gebied. Zo vind je een vergelijkbaar construct aan het einde van een eiwit, het 3’-UTR genoemd.
Er valt veel te zeggen over het 3’-UTR, maar hier citeer ik Wikipedia: “Het 3’ niet-getransleerde gebied heeft een cruciale rol bij genexpressie door de lokalisatie, stabiliteit, export en translatie-efficiëntie van een mRNA te beïnvloeden .. ondanks onze huidige kennis van 3’-UTR’s zijn ze nog steeds een relatief mysterie”.
Wat we wel weten is dat bepaalde 3’-UTR’s heel goed zijn in het bevorderen van eiwitexpressie. Volgens het WHO-document is het 3’-UTR in het BioNTech/Pfizer-vaccin gekozen uit “de amino-terminale versterker van gesplitst (AES) mRNA en het mitochondriaal gecodeerde 12S ribosomaal RNA om de stabiliteit van het RNA en een hoge eiwitproductie te garanderen”. En daarop zeg ik: goed gedaan.
Het einde van mRNA is gepolyadenyleerd. Dit is een mooie manier om te zeggen dat het op veel AAAAAAAAAAAAAAAAAAA’s eindigt. Het lijkt erop dat zelfs mRNA genoeg heeft van 2020.
mRNA kan vele keren opnieuw worden gebruikt, maar wanneer dit gebeurt gaan aan het einde ook enkele A’s verloren. Wanneer er geen A’s meer zijn, functioneert het mRNA niet meer en wordt het weggegooid. Op deze manier biedt de ‘poly-A’-staart bescherming tegen verval.
Er zijn onderzoeken gedaan om te achterhalen wat het optimale aantal A’s is aan het einde van mRNA-vaccins. In de openbaar toegankelijke literatuur heb ik gelezen dat dit aantal A’s rond de 120 ligt.
Het BNT162b2-vaccin eindigt als volgt:
****** ****
UAGCAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAGCAUAU GACUAAAAAA AAAAAAAAAA
AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAA
Dit zijn 30 A’s, gevolgd door een ’linker’ van 10 nucleotiden (GCAUAUGACU) en daarna nog 70 A’s.
Ik vermoed dat we hier het resultaat zien van verdere gepatenteerde optimalisatie om de eiwitexpressie nog verder te verbeteren.
Samenvatting
Nu weten we wat de exacte mRNA-inhoud is van het BNT162b2-vaccin, en van de meeste delen begrijpen we waarom ze aanwezig zijn:
- De ‘cap’ om ervoor te zorgen dat het RNA eruitziet als normaal mRNA
- Een bekend, succesvol en geoptimaliseerd 5’ niet getransleerd gebied (UTR)
- Een codon-geoptimaliseerde signaalpeptide om het Spike-eiwit naar de juiste plaats te sturen (100% gekopieerd van het oorspronkelijke virus)
- Een codon-geoptimaliseerde versie van de oorspronkelijke Spike, met twee ‘Proline’-vervangingen die ervoor zorgen dat het eiwit in de juiste vorm verschijnt
- Een bekend, succesvol en geoptimaliseerd 3’ niet-getransleerd gebied (UTR)
- Een ietwat mysterieuze poly-A-staart met daarin een onverklaarbare ’linker’
Door de codon-optimalisatie worden veel G’s en C’s toegevoegd aan het mRNA. Daarnaast wordt Ψ (1-methyl-3’-pseudouridylyl) in plaats van U gebruikt om ons immuunsysteem te omzeilen. Zo blijft het mRNA lang genoeg aanwezig en kunnen we het immuunsysteem daadwerkelijk trainen.
Verder lezen en kijken
In 2017 heb ik een twee uur durende presentatie gegeven over DNA, die je hier kunt bekijken. Net als dit artikel is deze video gericht op IT’ers.
Daarnaast beheer ik sinds 2001 een pagina over DNA voor programmeurs.
Misschien heb je ook interesse in deze introductie van ons geweldige immuunsysteem.
Tot slot bevat deze lijst van mijn blogposts behoorlijk wat informatie met betrekking tot DNA, SARS-CoV-2 en COVID.